深入介绍 Krita 的快速草稿描线插件
快速草稿描线插件
简介
这个项目的初衷是为用户提供一个好用的草稿清理和描线辅助工具。它基于 Simo 和 Sierra 在 2016 年发表的一篇研究论文 开发,使用了神经网络技术 (如今常常被笼统地叫做“AI”)。我们与 Intel 合作开发了该插件。目前它仍在实验阶段,不过您现在即可试用并体验效果。
我们会在下文中展示一些实际使用此插件的处理草稿后的结果。不同的草稿的处理效果有所差异,可以胜任从照片中提取颜色较淡的铅笔素描、清理线条以及生成漫画风格的描线结果。
我们自行训练了插件中使用的模型。模型数据集的所有数据均由自愿为我们提供图像并同意此用途的人士捐赠。我们没有在数据集中包含其他任何数据。此外,插件将在本地机器上运行,不需要互联网连接、连接服务器或者注册账户。目前该插件仅能在 Windows 和 Linux 系统中运行,但我们将设法使其在 macOS 上可用。
用例
此插件可以将多根线条平均成单一、明确的黑色线条,但最终效果可能会模糊或不均匀。即便如此,在许多情况下,它仍然比仅使用色阶滤镜 (常用于提取铅笔素描的线条) 的效果更好。在使用此插件处理之后使用色阶滤镜可能有助于降低模糊程度。由于此插件在白色画布和灰-黑色线条上的效果最佳,因此对于通过拍照获取的铅笔素描或颜色非常淡的素描草稿,在使用此插件之前先应用色阶滤镜可以改善处理效果。
提取拍照后的铅笔草稿
这是使用色阶滤镜对草稿进行典型处理以提取线条 (结果导致图像的一部分出现阴影) 后的效果:

sketch_girl_original_procedure_comparison_small1843×1209 165 KB
草图由 Tiar 绘制 (链接到其 Krita 国际画师论坛用户档案页面)
这是使用此插件的 SketchyModel 模型处理后的效果 (色阶滤镜 → 插件处理 → 色阶滤镜):

sketch_girl_new_procedure_comparison_small1843×2419 267 KB
处理效果对比 (黑线):

sketch_girl_procedures_comparison_small1920×1260 215 KB
另一种可能的结果是在完成插件处理后不使用色阶滤镜强制生成黑色线条,这可以产生更自然、更接近铅笔画的效果,同时保持页面下半部分空白:

sketch_girl_after_plugin_small1536×2016 161 KB
美漫风格描线
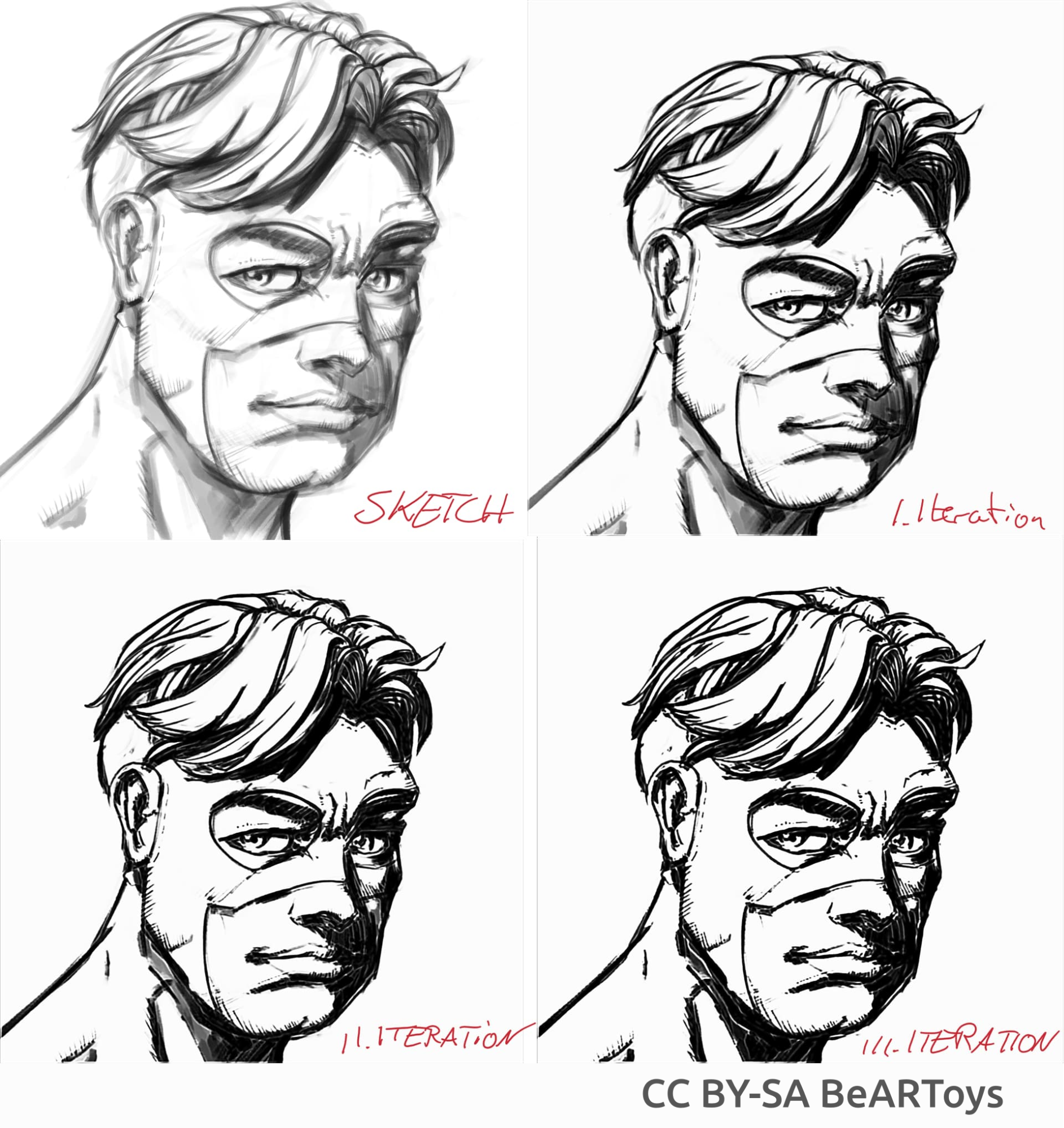
超英风格男性头像,作者:BeARToys

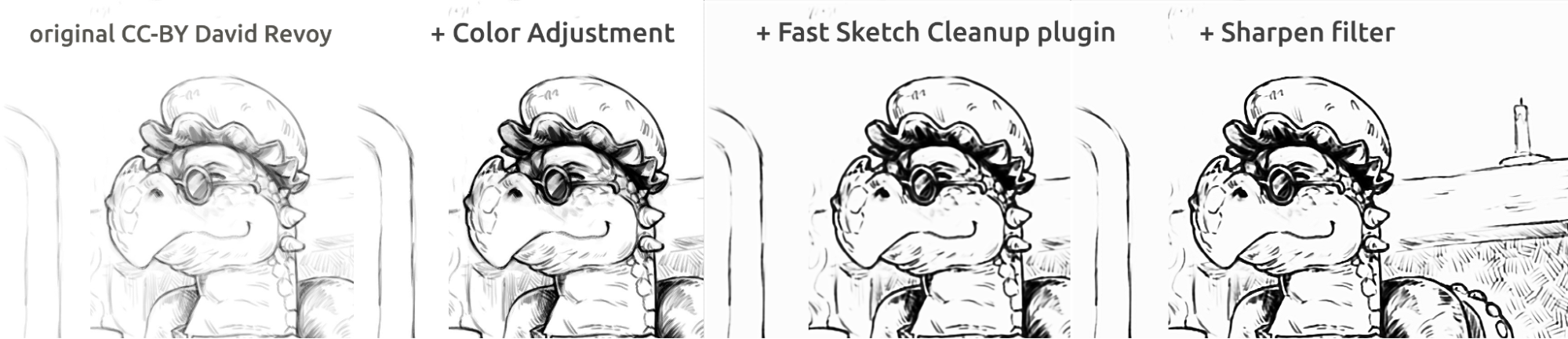
上图为传统连环画风格的描线处理结果。插件的处理结果相比起原图显得有点模糊,可以使用锐化滤镜进一步增强。此草稿作者为:David Revoy (CC-BY 4.0)。
清理线稿
以下是我绘制的示例草图在插件中处理结果,展示了插件的优缺点。下面的所有图片都是使用 SketchyModel 模型处理的。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flower_001_detail681×456 22.1 KB
{kind=link}

portrait_man_portrait_2_comparison_2_small1305×505 139 KB
{kind=link}

portrait_man_portrait_2_detail646×1023 26.6 KB
{kind=link}
以上所有图像的作者为:Tiar (链接到其 Krita 国际画师论坛用户档案页面)
在下面的图像中,你可以看到此模型是如何区分较淡的线条并增强较粗的线条,使鱼鳞更加明显。理论上,你可以使用色阶滤镜来实现这一点,但在实际使用会发现它要劣于插件处理的效果,因为插件的模型会考虑线条的局部强度。
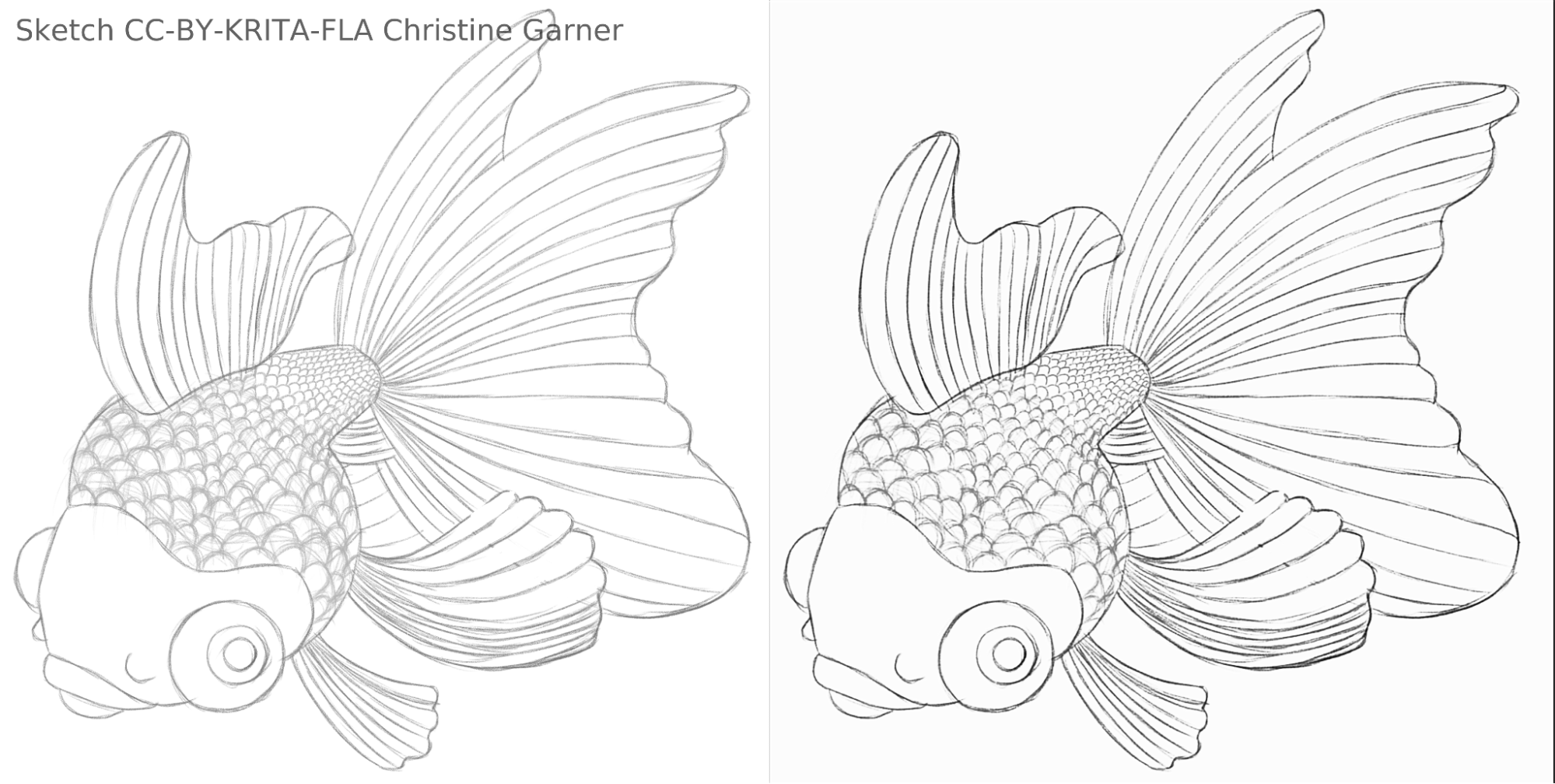
fish_square_sketchy_comparison_small1920×968 156 KB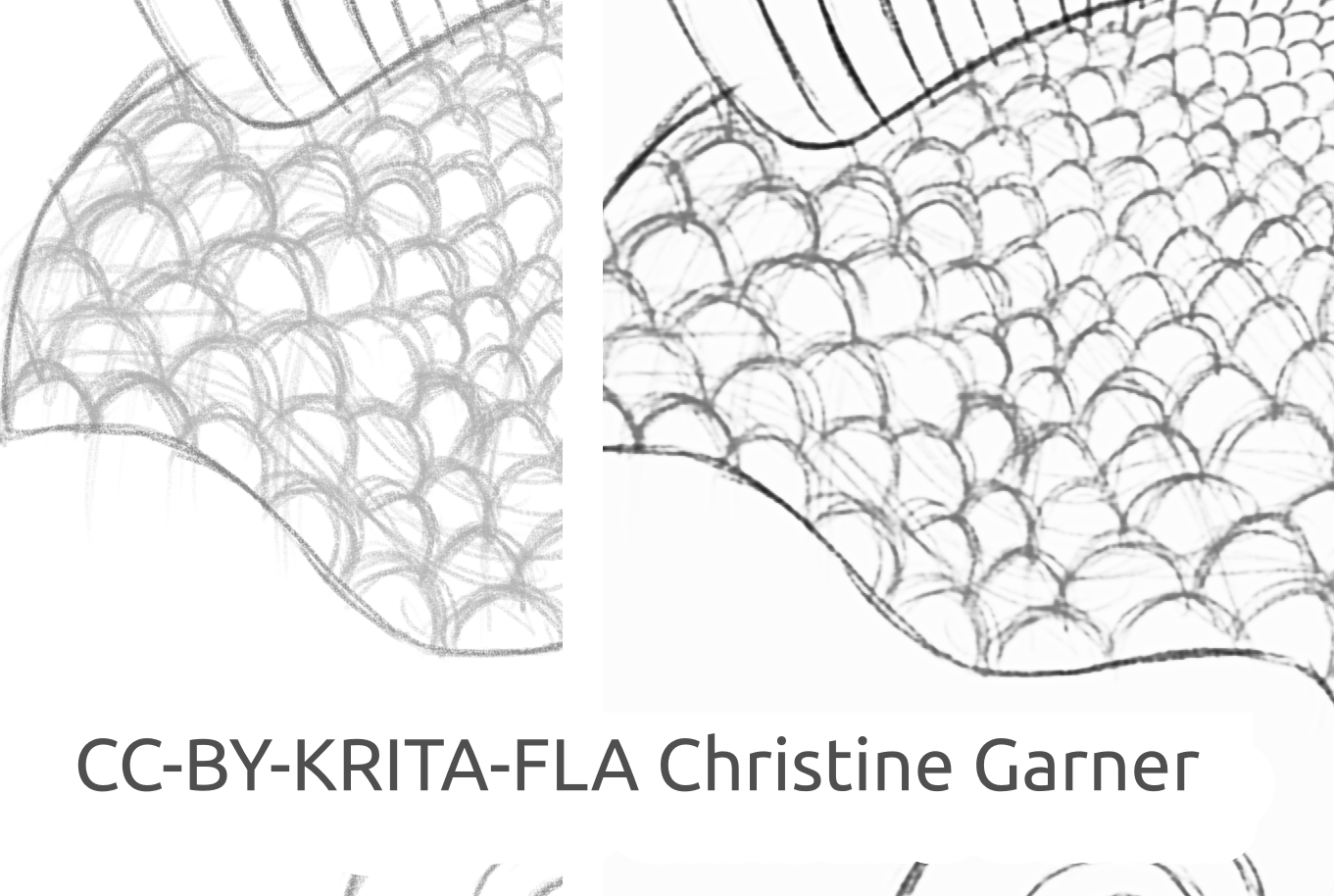
{kind=link}
金鱼草稿作者:Christine Garner (链接到其个人网站)
如何在 Krita 中使用此插件
请按照以下指引在 Krita 中使用快速草稿描线插件:
- 准备 Krita:
- Widnows 系统:
- 预装此插件的 Krita 测试版:https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.zip
- 分别安装 Krita 和此插件:
- 下载 Krita 5.2.6 的免安装版 (或者相似的版本 - 应该都能工作)
- 单独下载快速草稿描线插件:https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- 将插件压缩包中的内容解压到 krita-5.2.6/ 文件夹中 (保持文件夹结构)。
- 前往 设置 → 配置 Krita → Python 插件管理器,启用 Fast Sketch Cleanup (快速草稿描线) 插件,然后重新启动 Krita。
- Linux 系统:
- 下载预装此插件的 Krita 测试版 AppImage 软件包:https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
- Widnows 系统:
- (可选) 如果您的设备带有 NPU,请安装该 NPU 的驱动程序 (实际上仅在 Linux 上使用非常新的 Intel CPU 时才需要此步骤):Intel® NPU 的 OpenVINO™ 文档中的配置指引 (提示:NPU 并非硬性要求,您依然可以在 CPU 或 GPU 上使用此插件)
- 运行插件:
- 打开或创建一个带有灰色或白色笔画的白底画布 (请注意,该插件使用的是画布视图的显示内容,而不是当前图层的内容)。
- 前往 工具 → Fast Sketch Cleanup (快速草稿描线)
- 选择模型,程序将自动按照您选择的模型为您配置高级选项。
- 等待程序完成处理 (对话框将在处理完成后自动关闭)。
- 插件将把生成的结果创建为新图层。
处理建议
目前建议使用 SketchyModel.xml,因为在大多数情况下它比 SmoothModel.xml 的效果要好得多。
你需要确保背景颜色足够浅,并且你想要在处理结果中保留的线条颜色要相对更深 (最好是深灰色或黑色;浅灰色可能会导致很多线条被漏掉)。在操作之前使用“色阶”等滤镜处理一遍原稿可能会带来更好的效果。
处理结束后,您还可以按需使用色阶、锐化等滤镜进一步增强效果。
技术细节
特有需求
首先,这个插件必须能够在各种尺寸的画布上运行。这意味着它的神经网络不能包含常见于图像处理神经网络中的密集连接/完全连接的线性层 (这些层需要输入特定大小的图像,并且对于同一像素,其位置不同会导致产生不同的结果),只能包含卷积、池化或其他类型的不管像素在画布上的位置也依然能产生相同结果的层。幸运的是,Simo 和 Sierra 在 2016 年发表的一篇论文 恰好描述了一种符合此特征的神经网络。
另一个挑战是我们无法直接使用上述论文作者所制作的模型,因为它与 Krita 的许可证不兼容,我们也无法直接使用他们所描述的模型类型,因为其中一个模型文件的体积几乎与 Krita 本身一样大,训练过程将耗费很长时间。我们需要一种效果相当甚至更好的模型,而且它必须足够小,这样我们才能把它添加到 Krita 中而不至于使得软件包变大一倍。(尽管理论上我们也可以像其他一些公司那样使用外部服务器执行处理过程,但我们不想这样做。这种做法或许能解决一部分问题,但它也会带来许多其他额外的复杂挑战。而且我们希望用户可以在无需依赖我们的服务器和互联网的情况下在本地使用这个插件)。另外,它的模型必须具有足够快的运行速度,而且不会消耗过多的内存/显存。
最后,我们当时没有任何可用的数据集。Simo 和 Sierra 使用的数据集是设想图像全部使用宽度和透明度恒定的线条绘制的,这意味着训练后的结果也具有这些特性。而我们的插件需要处理结果符合手绘的特征,这意味着线条宽度要有变化,线条末端的透明度也要有变化,因此我们的数据集必须包含这些类型的图像。由于我们没有发现任何符合我们对许可证和数据收集流程要求的数据集,我们于是向 Krita 的社区寻求帮助,您可以在 Krita 国际画师论坛的相关讨论串中了解详情:https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401。
我们使用的完整数据集的链接可在下文的“数据集”一节中找到。
模型架构
所有主层要么是卷积层,要么是反卷积层 (位于模型的末尾)。除了最后一层之外,在每个卷积/反卷积层之后都有一个 ReLU 激活层,在最后一个卷积层之后有一个 sigmoid 激活层。
使用的 Python 软件包:Pillow、Numpy、PyTorch 和 Openvino
Numpy 是一个用于处理各种数组和高级数组操作的标准程序库,我们使用 Pillow 读取图像并将其转换为 Numpy 数组和反向转换。在训练阶段,我们使用了 PyTorch,而在 Krita 插件中,我们使用了 Openvino 进行推理 (即通过插件的神经网络进行处理)。
使用 NPU 进行推理

该表格显示了 Intel 提供的 Python 包中的 OpenVINO 提供的基准测试工具 benchmark_app 的结果。该工具在随机数据上对模型进行了隔离测试。如图所示,在同一台机器上,NPU 的处理速度要比 CPU 快好几倍。
另一方面,引入 NPU 也带来了新的挑战:目前唯一能在 NPU 上运行的模型是静态模型,这意味着在将模型保存到文件时,输入大小是已知的。为了解决这个问题,插件首先将画布分割成指定大小的多个部分 (该大小取决于模型文件),然后依次处理所有部分,最后将结果拼接在一起。为了避免拼接区域周围的失真,所有部分的切割边缘都留有一定的余量,它们将在后期被裁剪。
如何自行训练模型
要自行训练模型,您需要具备一定的计算机技术,以及一定数量的成对图片 (输入草图和预期输出的线稿) 以及一台性能强大的计算机。您也可能会需要大量的存储空间,如果空间不足,您也可以移除不再需要的旧模型以释放硬盘空间。
驱动程序和准备工作
你需要安装 Python3 以及以下软件包:Pillow、openvino、numpy、torch。为了对模型进行量化,你还需要安装 nncf 和 sklearn 。程序会在缺少任何软件包时报错,请按照它的提示安装所有所需的软件包。
如果你使用的是 Windows 操作系统,那么你可能已经安装了 NPU 和独立 GPU 的驱动程序。如果你使用的是 Linux 操作系统,那么在使用 NPU 之前可能需要先安装驱动程序:https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html .
此外,如果您想使用集成显卡进行训练 (这可能仍然比在CPU上快得多),您可能需要使用 IPEX 之类的工具,该工具允许 PyTorch 使用“XPU”设备,即您的集成显卡。由于我个人的 Python 版本高于 intel 后面提供的安装指引,因此无法对其进行测试或推荐,详情请见:https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu 。
安装的正确性检查如下:
python3 -c "import torch; import intel_extension_for_pytorch as ipex; print(f'Packages versions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Devices:'); print(f'Torch XPU device count: {torch.xpu.device_count()}'); [print(f'[Device {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
它应该显示出大于 0 个的带有某些基本属性的设备。
如果你成功在你的机器上运行 XPU 设备,你接下来还要编辑训练脚本来使其能够使用该设备:https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html (您很可能只需要添加这一行命令:
import intel_extension_for_pytorch as ipex
到脚本的顶部,位于“import torch”之下,并且在调用脚本时使用“xpu”作为设备名称,应该就可以正常工作了。不过仍如我之前所说,这些脚本尚未针对此用途进行过测试。
数据集
你需要一些图像来训练你的模型。这些图像必须成对出现,每一对中都必须包含一张草稿 (输入) 和它的线稿图 (预期输出)。数据集的质量越高,结果就越好。
在训练之前,最好对数据进行增强:这意味着要对图像进行旋转、放大或缩小,以及水平/垂直翻转。目前,数据增强脚本还会对图像进行反相,因为我们假设在反相后的图片上进行训练可以更快地获得结果 (考虑到黑色代表零即没有信号,我们希望将其作为背景,这样模型就会学习线条部分,而不是线条周围的背景部分)。
数据增强脚本的使用方法将在下文的“训练”一节详细说明。
这是我们使用的数据集 (如果您打算使用它,请详细阅读它的许可证): https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
模型和其他参数的选择
想要快速得到结果,可以使用 tooSmallConv;如果你有更多的时间和资源,typicalDeep 可能更适合你。如果你有强大的 GPU,也可以尝试 original 或 originalSmaller,前者代表了 Simo 和 Sierra 2016 年在 SIGGRAPH 上发表的文章中对该模型的原始描述,后者则是该描述的小型版本。
使用 adadelta 作为优化器。
你可以使用 blackWhite 或 mse 作为损失函数;mse 是经典用法,但是 blackWhite 可能速度更快,因为它降低了完全白色或完全黑色区域的相对误差 (基于预期输出图片)。
训练
克隆此软件仓库:https://invent.kde.org/tymond/fast-line-art (at 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.git准备文件夹:
- 为训练数据创建一个新文件夹。
- 在该文件夹中执行:
python3 [软件库文件夹]/spawnExperiment.py --path [新文件夹的路径,可以是相对路径也可以是绝对路径] --note "[您对此次训练的个人注释]"
准备数据:
- 如果你已经有现成的增强数据集,请将其全部放入 data/training/ 和 data/verify/ 目录中,请记住,ink/ 和 sketch/ 子文件夹中的成对图片必须具有相同的名称 (例如,如果您用作数据的草稿图像文件名为 sketch.png,线稿图像文件名为 ink.png,您需要将放入 sketch/ 目录中的草稿图像重命名为 picture.png,并将放入 ink/ 目录中的线稿图像也重命名为 picture.png 以一一对应)。
- 如果您没有现成的增强数据集:
- 将所有原始数据放入 data/raw/ 文件夹中,请注意成对的图像应该具有完全相同的名称,并在名称前添加 ink_ 或 sketch_ 前缀 (例如,如果您的草稿图像文件名为 picture_1.png,线稿图像文件名为 picture_2.png,则需要分别将它们命名为 sketch_picture.png 和 ink_picture.png)。
- 执行数据准备程序脚本:
python3 [软件库文件夹]/dataPreparer.py -t taskfile.yml
这将对原始数据目录中的数据进行增强处理,从而使训练更加成功。
编辑 taskfile.yml 文件以适应您的需要。您可能需要更改的最重要的部分是:
- model type - 模型类型的代码名称,使用 tinyTinier、tooSmallConv、typicalDeep 或 tinyNarrowerShallow
- optimizer - 优化器的类型,使用 adadelta 或 sgd
- learning rate - 如果使用了 sgd,此项用于指定学习速率
- loss function - 损失函数的代码名称,使用 mse 是均方误差,使用 blackWhite 是基于 mse 的自定义损失函数,但对于目标图像像素值接近 0.5 的像素,损失函数略小。
执行训练命令:
python3 [repository folder]/train.py -t taskfile.yml -d "cpu"在 Linux 上,如果想要让训练脚本在后台运行,请在命令末尾添加“&”。如果它在前台运行,只需按下 Ctrl+C 即可暂停训练;如果它在后台运行,可以找到它的进程 ID (使用 jobs -l 命令或 ps aux | grep train.py 命令,返回的第一个数字就是进程 ID),然后使用 kill [process id] 命令来强制停止此进程。训练被停止后,您的训练结果数据将依然保存在前述的文件夹内,使用相同的训练命令即可继续训练过程。
转换模型为 openvino 模型:
python3 [repository folder]/modelConverter.py -s [输入大小,建议 256] -t [输入模型名称,来自 pytorch] -o [openvino 模型名称,结尾必须是 .xml]放置 .xml 和 .bin 模型文件到您的 Krita 的资源文件夹中 (在 pykrita/fast_sketch_cleanup 子文件夹中),与其他您要在此插件中使用使用的其他模型放在一起。