Занурення у додаток швидкого чищення ескіза Krita
Додаток швидкого чищення ескіза
Вступ
Ми розпочали цей проект з наміром надати користувачам інструмент, який допоможе створювати ескізи. Його засновано на [дослідницькій статті Simo & Sierra, опублікованій у 2016 році] (https://esslab.jp/~ess/publications/SimoSerraSIGGRAPH2016.pdf), і для роботи він використовує нейронні мережі (зараз їх зазвичай називають просто ШІ). Інструмент був розроблений у партнерстві з Intel і все ще вважається експериментальним, але ви вже можете скористатися ним і переконатися у результатах.
У розділі нижче наведено кілька реальних прикладів використання та результатів роботи додатка. Результати досить різні, але ним можна скористатися для вилучення тьмяних ескізів олівцем із фотографій, очищення ліній і малювання коміксів.
Що стосується моделі, яка використовується в інструменті, ми її навчили самі. Усі дані в наборі даних надано людьми, які самі надіслали нам свої зображення та погодилися на цей конкретний варіант використання. Інших даних ми не використовували. Крім того, коли ви використовуєте додаток, він обробляє дані локально на вашому комп'ютері, йому не потрібне інтернет-з'єднання, жоден сервер, а також не потрібен обліковий запис. Наразі він працює лише в Windows і Linux, але ми працюватимемо над тим, щоб зробити його доступним і в MacOS.
Користування
Він усереднює лінії в одну лінію та створює яскраві чорні лінії, але кінцевий результат може бути розмитим або нерівним. Однак у багатьох випадках це все одно працює краще, ніж просто використання фільтра «Рівні» (наприклад, для вилучення ескіза олівцем). Можливо, варто спробувати використати фільтр рівнів після використання додатка, щоб зменшити розмитість. Оскільки додаток найкраще працює з білим полотном і сіро-чорними лініями, у випадку сфотографованих олівцевих ескізів або дуже світлих ескізних ліній, можливо, було б добре також скористатися зміною рівнів перед використанням додатка.
Видобування даних із сфотографованого ескіза
Це результат стандартної процедури використання фільтра «Рівні» на ескізі для виокремлення ліній (що призводить до того, що з'являється тінь на частині зображення):

sketch_girl_original_procedure_comparison_small1843×1209 165 KB
Ескіз намальовано Tiar (посилання на профіль у KA)
Ось процедура користування додатком із SketchyModel (Рівні → додаток → Рівні):

sketch_girl_new_procedure_comparison_small1843×2419 267 KB
Порівняння (для чорних ліній):

sketch_girl_procedures_comparison_small1920×1260 215 KB
Іншим можливим результатом є просто зупинитися на застосуванні додатка без примусового вживання чорних ліній з використанням рівнів, що призводить до кращого, більш подібного на малювання олівцем вигляду, залишаючи нижню частину сторінки порожньою:

sketch_girl_after_plugin_small1536×2016 161 KB
Графіка у стилі коміксів
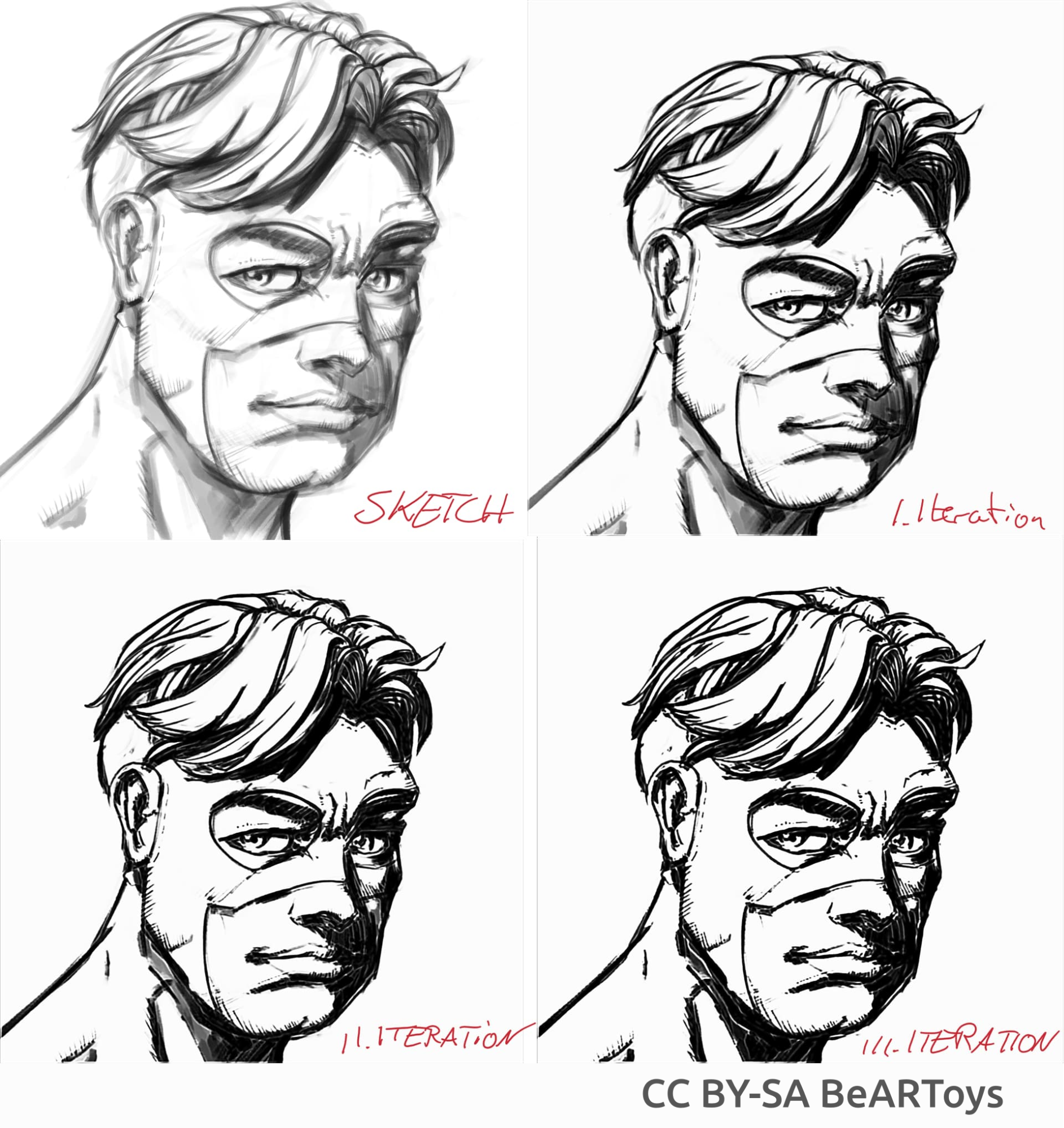
Малюнок чоловіка від BeARToys

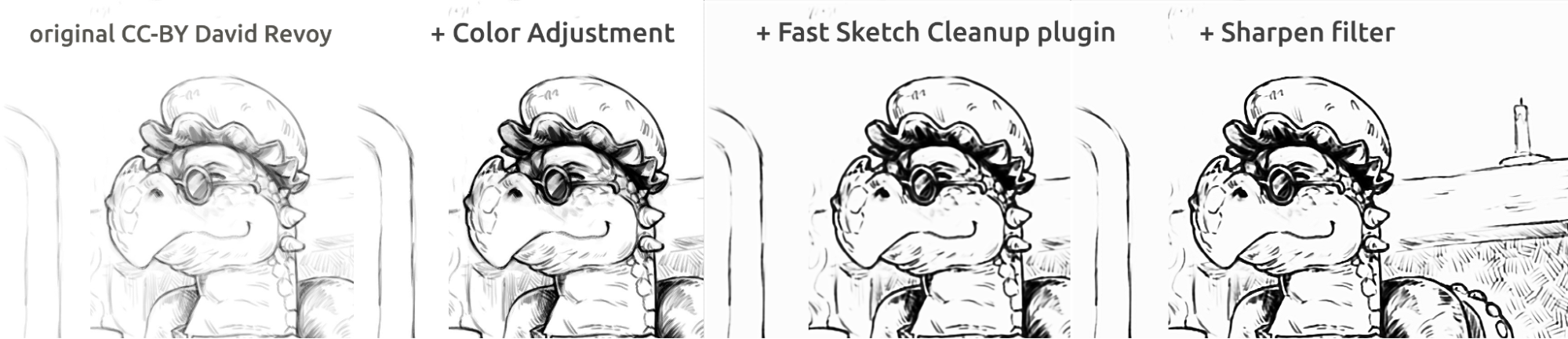
Тут на малюнках вище ви можете побачити чорнильний малюнок у стилі коміксів. Результат, який є трохи розмитим порівняно з оригіналом, можна додатково покращити за допомогою фільтра збільшення різкості. Ескіз дракона намалював David Revoy (CC-BY 4.0).
Чищення ліній
Приклади зроблених мною ескізів і результат роботи додатка, що показує сильні та слабкі сторони додатка. Усі зображення, наведені нижче, було створено за допомогою SketchyModel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flower_001_detail681×456 22.1 KB
{kind=link}

portrait_man_portrait_2_comparison_2_small1305×505 139 KB
{kind=link}

portrait_man_portrait_2_detail646×1023 26.6 KB
{kind=link}
Усі наведені вище зображення було створено Tiar (посилання на профіль на KA)
На малюнках нижче на лусці риби ви можете побачити, як модель розрізняє світлі лінії та посилює сильні лінії, роблячи луску більш виразною. Теоретично ви могли б зробити це за допомогою фільтра «Рівні», але на практиці результати були б гіршими, оскільки модель враховує локальну потужність лінії.
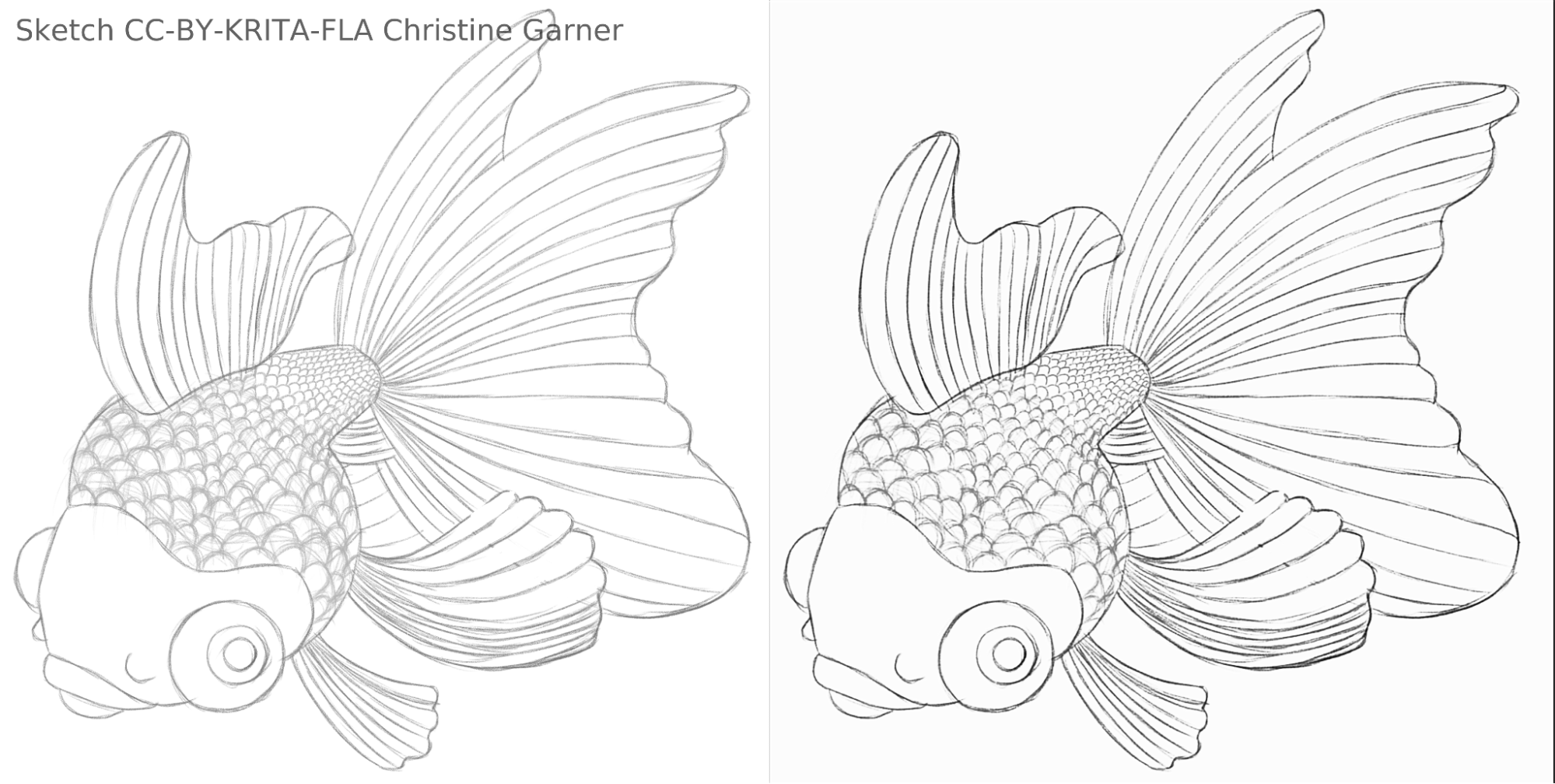
fish_square_sketchy_comparison_small1920×968 156 KB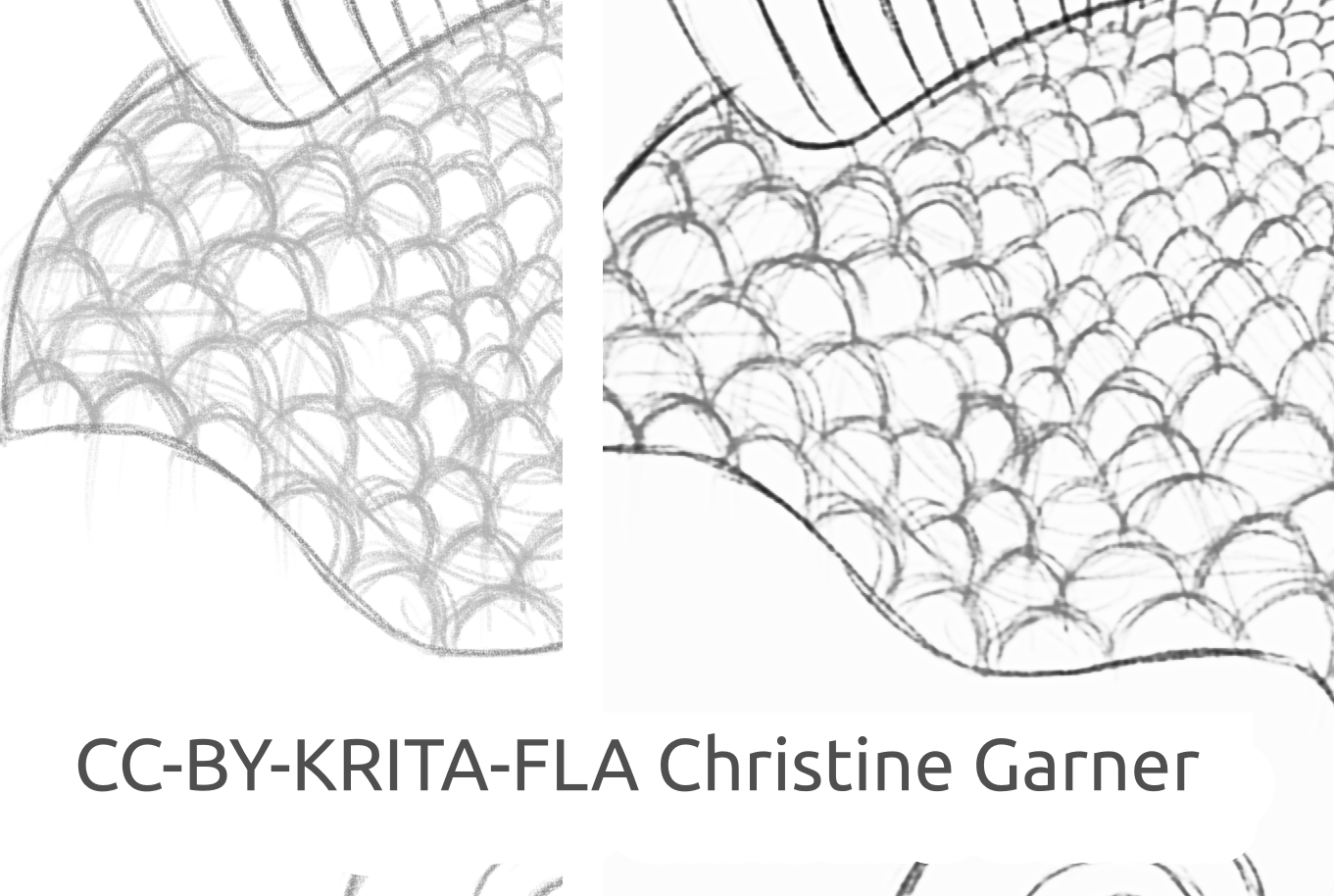
{kind=link}
Малюнок риби, який створено Christine Garner (посилання на портфоліо)
Як користуватися у Krita
Щоб скористатися додатком швидкого чищення ескіза у Krita, виконайте такі дії:
- Приготування Krita:
- У Windows:
- Або в одному пакеті: отримайте Krita 5.3.0-prealpha із уже включеним додатком швидкого чищення ескіза: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.z ip
- Або окремо:
- Отримайте портативну версію Krita 5.2.6 (або подібну версію - має також працювати)
- Отримайте окремою код додатка швидкого чищення ескізів тут: https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- Розпакуйте файл до теки krita-5.2.6/ (зберігаючи структуру підтек).
- Перейдіть у меню таким чином: «Параметри → Налаштувати Krita → Керування додатками Python», увімкніть додаток швидкого чищення ескізів і перезапустіть Krita.
- У Linux:
- Отримайте пакунок appimage: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
- У Windows:
- (Необовʼязково) Установіть драйвери NPU, якщо на вашому пристрої є NPU (практично це необхідно лише в Linux, якщо у вас дуже новий процесор Intel): Конфігурації для Intel® NPU з OpenVINO™ — документація OpenVINO™ (примітка: попри все це ви можете запускати додаток на ЦП або GPU, не вимагає NPU)
- Запуск додатка:
- Відкрийте або створіть біле полотно із сіро-білими штрихами (зауважте, що додаток використає поточну проєкцію полотна, а не поточний шар).
- Перейдіть у меню «Інструменти → Швидке чищення ескіза»
- Виберіть модель. Значення додаткових параметрів буде вибрано автоматично.
- Зачекайте на завершення обробки (діалогове вікно буде закрито автоматично).
- Додаток створить новий шар із результатами роботи.
Поради щодо обробки
У поточній версії краще просто скористатися SketchyModel.xml, у більшості випадків цей варіант значно кращий за SmoothModel.xml.
Ви маєте переконатися, що тло досить яскраве, а лінії, які ви хочете зберегти у результаті, відносно темні (дещо темно-сірі або чорні; світло-сірий може призвести до багатьох пропущених ліній). Було б доцільно заздалегідь використати такий фільтр, як «Рівні».
Після обробки може виникнути потреба в удосконаленні результатів або за допомогою фільтра рівнів, або за допомогою фільтра збільшення різкості, залежно від результатів.
Технологія і наукове підґрунтя
Унікальні вимоги
Першою унікальною вимогою було те, що додаток мав працювати на полотнах усіх розмірів. Це означало, що мережа не могла мати жодних щільних/повністю або щільно зв’язаних лінійних шарів, які дуже поширені в більшості нейронних мереж обробки зображень (які вимагають введення певного розміру та дають різні результати для того самого пікселя залежно від його розташування), лише згортки, об’єднання або подібні шари, які дають однакові результати для кожного пікселя полотна, незалежно від розташування. На щастя, [документ Simo & Sierra, опублікований у 2016 році] (https://esslab.jp/~ess/publications/SimoSerraSIGGRAPH2016.pdf) описує мережу саме так.
Ще одна проблема полягала в тому, що ми не могли реально використати модель, яку вони створили, оскільки вона не була сумісна з умовами ліцензування Krita, і ми навіть не могли насправді використати точний тип моделі, який вони описали, оскільки що один із цих файлів моделі був би майже таким великим як Krita, і навчання за ним триватиме дуже довго. Нам потрібно було щось, що працювало б так само добре, якщо не краще, але достатньо маленьке, щоб його можна було додати до Krita, не роблячи пакунок вдвічі більшим. (Теоретично ми могли б зробити так, як інші компанії, і зробити обробку на якомусь сервері, але це було не те, чого ми хотіли. І навіть якби це вирішило деякі з наших проблем, це б призвело до багатьох окремих проблем. Крім того, ми хотіли, щоб наші користувачі могли використовувати його локально, не покладаючись на наші сервери та інтернет). Крім того, модель повинна була бути досить швидкою, а також оптимізованою щодо споживання RAM/VRAM.
Крім того, у нас не було жодного набору даних, який ми могли б використати. Симо і Сьєрра використовували набір даних, де всі очікувані зображення були намальовані з використанням сталої товщини лінії та прозорості, що означало, що результати навчання також мали ці якості. Нам хотілося щось, що виглядало б більш намальованим від руки, із різною шириною ліній або напівпрозорими кінцями ліній, тому наш набір даних мав містити такі зображення. Оскільки нам не було відомо про жодні набори даних, які б відповідали нашим вимогам щодо ліцензування та процесу збору даних, ми звернулися по допомогу до нашої власної спільноти. Ви можете прочитати тему Krita Artists про це: [https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401](https://krita-artists.org/t/ call-for-donation-of-artworks-for-the-fast-line-art-project/96401) .
Посилання на повний набір даних наведено нижче у розділі «Набір даних».
Архітектура моделі
Усі основні шари є згортковими або розгортковими (у кінці обробки моделі). Після кожного шару, крім останнього, є шар активації ReLu, а після останньої згортки — сигмоподібний шар активації.
Використані пакунки Python: Pillow, Numpy, PyTorch і Openvino
Numpy — це стандартна бібліотека для всіх типів масивів і розширених операцій з масивами, і ми використовували Pillow для читання зображень і перетворення їх у масиви numpy і навпаки. Для навчання ми використовували PyTorch, тоді як у додатку Krita ми використовували Openvino для отримання результатів (обробка через мережу).
Використання NPU для результатів

У цій таблиці показано результат роботи benchmark_app, інструменту, який постачається разом із пакетом python openvino від Intel. Він перевіряє модель ізольовано на випадкових даних. Як ви можете бачити, варіант з NPU був у кілька разів швидшим, ніж з центральним процесором на тому самому комп'ютері.
З іншого боку, запровадження NPU додало труднощів: єдині моделі, які можуть працювати на NPU, — це статичні моделі, тобто вхідний розмір має бути відомим на момент збереження моделі у файлі. Щоб вирішити цю проблему, додаток спочатку розрізає полотно на менші частини заданого розміру (який залежить від файла моделі), а потім продовжує обробку всіх і, нарешті, зшиває результати. Щоб уникнути артефактів на ділянках поруч зі швом, усі деталі вирізаються з невеликим запасом, а потім обрізається край.
Як навчити власну модель
Щоб навчити власну модель, вам знадобляться певні технічні навички, пари зображень (вхідні та очікувані вихідні) і потужний комп’ютер. Вам також може знадобитися досить багато місця на жорсткому диску, хоча ви можете просто вилучити непотрібні старі моделі, якщо у вас виникнуть проблеми з нестачею місця.
Драйвери і приготування
Вам слід буде встановити Python3 і наступні пакети: Pillow, openvino, numpy, torch. Для квантування моделі вам також знадобляться nncf і sklearn. Якщо я щось пропустив, пакунок поскаржиться, тому просто встановіть ці пакети, про які буде згадано.
Якщо ви використовуєте Windows, у вас, ймовірно, є драйвери для NPU і виокремленого графічного процесора. У Linux може виникнути потребу у встановленні драйверів NPU, перш ніж ви зможете користуватися додатком: https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html .
Крім того, якщо ви хочете використовувати для навчання інтегрований графічний процесор (який все ще може бути значно швидшим, ніж на центральний процесор), вам, ймовірно, слід використовувати щось подібне до IPEX, що надає змогу PyTorch використовувати пристрій «XPU», який є просто вашим інтегрований графічний процесор. Це не перевірено та не рекомендовано, оскільки я особисто не зміг ним скористатися, оскільки моя версія Python була вищою, ніж очікується в інструкції, але є настанови: [https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu](https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10 %2Bxpu) .
Перевірка працездатності встановлених компонентів:
python3 -c "import torch; import intel_extension_for_pytorch as ipex; print(f'Packages versions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Devices:'); print(f'Torch XPU device count: {torch.xpu.device_count()}'); [print(f'[Device {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
Має бути показано більше 0 пристроїв із деякими основними властивостями.
Якщо вам вдасться змусити пристрій XPU працювати на вашому комп'ютері, вам усе одно доведеться змінити навчальні скрипти, щоб скрипти могли ним користуватися: https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html (швидше за все, вам слід просто додати цей рядок:
import intel_extension_for_pytorch as ipex
до скрипту на самому початку, просто під «import torch», і скористатися «xpu» як назвою пристрою під час виклику скрипту, і це має працювати. Але, як я вже сказав, скрипти на це не перевіряли.
Набір даних
Щоб навчити свою модель, вам знадобляться кілька зображень. Малюнки має бути створено парами, кожна пара має містити ескіз (вхідні дані) та графічне зображення (очікувані результати). Що краща якість набору даних, то кращі результати.
Перед навчанням найкраще удосконалити дані: це означає, що зображення слід повернути, масштабувати вгору або вниз і віддзеркалити. У поточній версії скрипт удосконалення даних також виконує інверсію з припущенням, що навчання на інвертованих зображеннях дасть результати швидше (враховуючи, що чорний означає нуль, тобто відсутність сигналу, і ми хотіли б, щоб це було тло, щоб моделі вивчали лінії, а не тло навколо ліній).
Як користуватися скриптом удосконалення даних пояснено у докладних настановах до навчальної частини.
Ось набір даних, яким ми скористалися (будь ласка, якщо ви хочете ним скористатися, уважно прочитайте умови ліцензування): https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
Вибір моделі та інших параметрів
Щоб отримати результати швидше, скористайтеся tooSmallConv; якщо у вас більше часу та ресурсів, краще може бути типовий Deep. Якщо у вас є потужний графічний процесор, ви можете спробувати original або originalSmaller, які відповідають початковому опису моделі зі [статті SIGGRAPH Симо і Сьєрри, 2016](https://esslab.jp/~ess/publications/ SimoSerraSIGGRAPH2016.pdf), а також її меншої версію.
Скористайтеся adadelta як засобом оптимізації.
Ви можете використовувати blackWhite або mse як функцію втрат; mse є класичним, але blackWhite може дати результати швидше, оскільки він зменшує відносну похибку на повністю білих або повністю чорних областях (на основі очікуваного вихідного зображення).
Навчання
Створіть клон сховища у https://invent.kde.org/tymond/fast-line-art (на 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.gitДалі, приготуйте теку:
- Створіть теку для тренування.
- У теці віддайте команду:
python3 [шлях до сховища]/spawnExperiment.py --path [шлях до нової теки, відносний або абсолютний] --note "[ваша особиста нотатка щодо експерименту]"
Приготування даних:
- Якщо у вас є наявний удосконалений набір даних, розмістіть його у data/training/ і data/verify/, пам’ятаючи, що парні зображення у підтеках ink/ і sketch/ повинні мати однакові назви (наприклад, якщо у вас є sketch.png і ink.png як дані, вам потрібно помістити один у sketch/ як picture.png, а інший у ink/ як picture.png, щоб створити пару).
- Якщо у вас немає розширеного набору даних:
- Помістіть усі свої необроблені дані в data/raw/, пам’ятаючи, що парні зображення повинні мати однакові назви з доданим префіксом ink_ або sketch_ (наприклад, якщо у вас є picture_1.png малюнок ескіза та picture_2.png, будучи малюнком чорнилом, вам слід назвати їх sketch_picture.png та ink_picture.png відповідно.)
- Запустіть скрипт приготування даних:
python3 [тека сховища]/dataPreparer.py -t taskfile.yml
У результаті буде удосконалено дані у каталозі необроблених даних із метою ефективнішого навчання.
Змініть файл taskfile.yml відповідно до ваших потреб. Найважливішими частинами, які варто змінити, є такі:
- тип моделі - кодова назва типу моделі, можна використовувати tinyTinier, tooSmallConv, typicalDeep або tinyNarrowerShallow
- оптимізатор - тип оптимізатора, adadelta або sgd
- швидкість навчання - швидкість навчання для використаного sgd
- функція втрат - кодове ім'я для функції втрат, скористайтеся mse для середньоквадратичної помилки або blackWhite для спеціальної функції втрат на основі mse, але трохи менше для пікселів, де цільове значення пікселя зображення близьке до 0.5
Запуск навчального коду:
python3 [тека сховища]/train.py -t taskfile.yml -d "cpu"У Linux, якщо ви хочете, щоб скрипт працював у фоновому режимі, додайте «&» в кінці. Якщо скрипт працює в основному режимі, ви можете призупинити навчання, просто натиснувши ctrl+C, а якщо він працює у фоновому режимі, знайдіть ідентифікатор процесу (за допомогою команди «jobs -l» або «ps aux | grep train.py», перше число буде ідентифікатором процесу) і завершіть його за допомогою команди «kill [ідентифікатор процесу]». Ваші результати залишаться в теці, і ви зможете відновити навчання за допомогою тієї ж команди.
Перетворіть модель на модель openvino:
python3 [тека сховища]/modelConverter.py -s [розмір вхідних даних, рекомендовано 256] -t [назва моделі вхідних даних, з pytorch] -o [назва моделі openvino, має закінчуватися на .xml]Розмістіть файли моделі .xml і .bin у вашій теці ресурсів Krita (у підтеці pykrita/fast_sketch_cleanup) поряд з іншими моделями, щоб використовувати їх у додатку.