Fördjupning i insticksprogrammet Snabb skissförbättring för Krita
Insticksprogrammet Snabb skissförbättring
Inledning
Vi startade projektet med avsikten att ge användarna ett verktyg som är användbart för att färga skisser. Det är baserad på en forskningsartikel av Simo & Sierra publicerad 2016, och den använder neurala nätverk (nu vanligen kallad AI) för att fungera. Verktyget har utvecklats i samarbete med Intel och det anses fortfarande vara experimentellt, men man kan redan använda det och se resultatet.
I avsnittet nedan finns några verkliga exempel på användarfall och resultaten från insticksprogrammet. Resultaten varierar, men den kan användas för att extrahera svaga blyertsskisser från foton, rensa upp linjer och färga serietidningar.
När det gäller modellen som används i verktyget tränade vi den själva. All data i datauppsättningar är donerad från personer som själva skickat sina bilder till oss och kommit överens om det specifika användarfallet. Vi har inte använt någon annan data. Dessutom, när man använder insticksprogrammet, bearbetar det lokalt på datorn, det kräver ingen internetanslutning, ansluter inte till någon server och inget konto krävs heller. För närvarande fungerar det bara på Windows och Linux, men vi kommer att arbeta med att göra det tillgängligt på MacOS också.
Användarfall
Det ger ett genomsnitt av linjerna till en linje och skapar starka svarta linjer, men slutresultatet kan bli suddigt eller ojämnt. I många fall fungerar det ändå bättre än att bara använda ett nivåfilter (till exempel för att extrahera blyertsskissen). Det kan vara en bra idé att använda nivåfiltret efter att ha använt insticksprogrammet för att minska suddigheten. Eftersom insticksprogrammet fungerar bäst med vit duk och gråsvarta linjer, vid fotograferade blyertsskisser eller mycket ljusa skisslinjer, kan det vara en bra idé att använda nivåer även innan insticksprogrammet används.
Extrahera fotograferad pennskiss
Här är resultatet av standardproceduren att använda nivåfiltret på en skiss för att extrahera linjerna (vilket resulterar i att en del av bilden får skuggan):

sketch_girl_original_procedure_comparison_small1843×1209 165 KB
Skissen ritades av Tiar (länk till KA-profil)
Här är proceduren som använder insticksprogrammet med SketchyModel (nivå → insticksprogram → nivå):

sketch_girl_new_procedure_comparison_small1843×2419 267 KB
Jämförelse (för svarta linjer):

sketch_girl_procedures_comparison_small1920×1260 215 KB
Ett annat möjligt resultat är att bara stanna vid insticksprogrammet utan att tvinga fram svarta linjer med hjälp av nivåer, vilket resulterar i ett snyggare, mer blyertsliknande utseende samtidigt som den nedre delen av sidan fortfarande är tom:

sketch_girl_after_plugin_small1536×2016 161 KB
Serietidningsliknande färgning
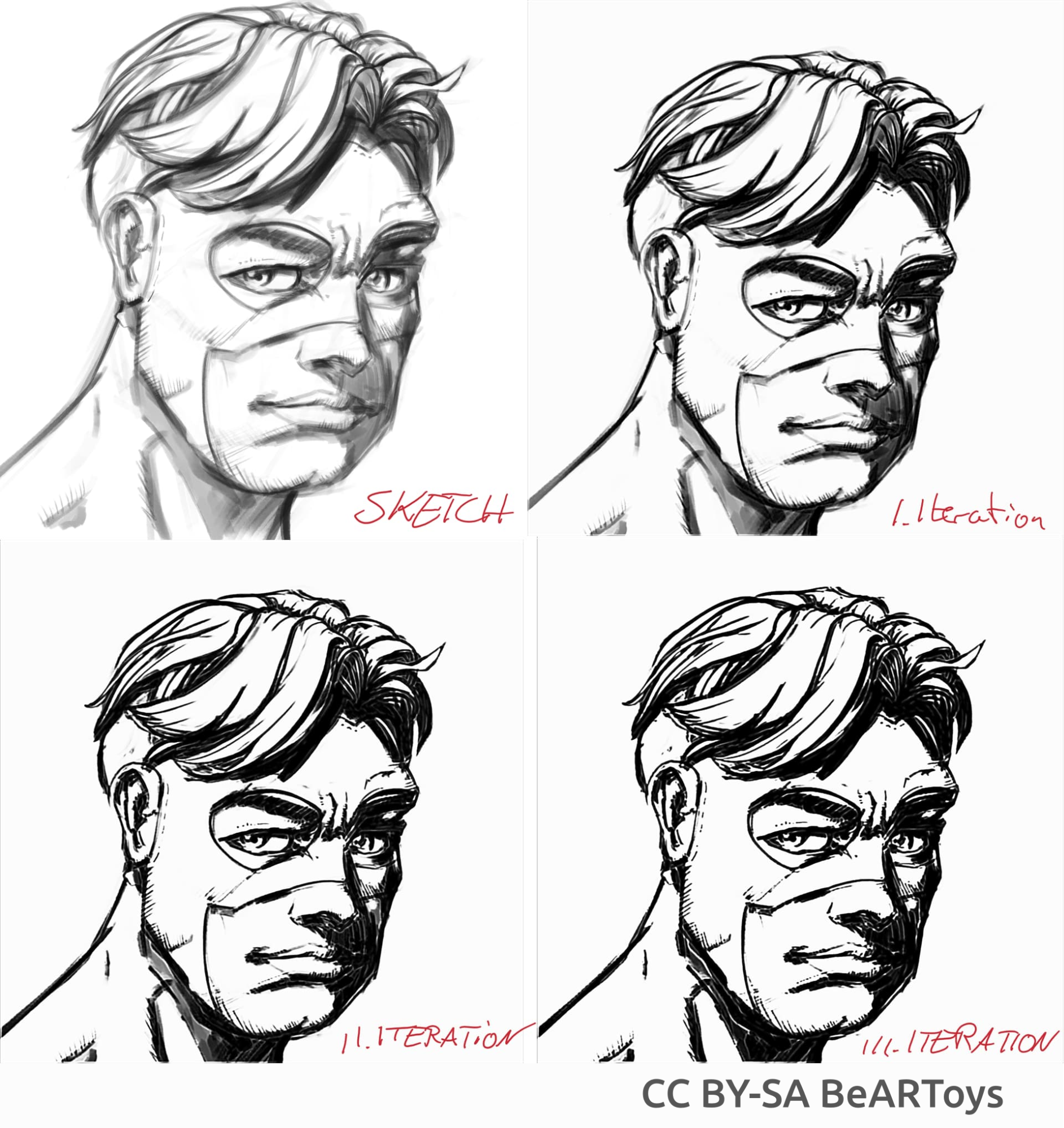
Bild av en man skapad av BeARToys

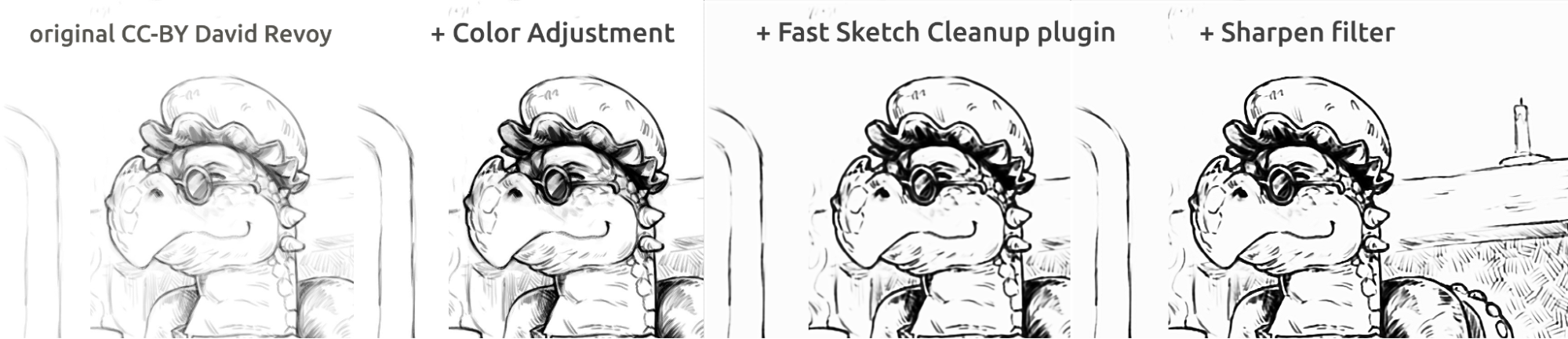
Här på bilderna ovan kan du se serietidningsstilen. Resultatet, som är lite suddigt jämfört med originalet, kan förbättras ytterligare genom att använda ett skärpefilter. Draken skissades av David Revoy (CC-BY 4.0).
Förbättra linjer
Exempel på skisser jag gjort och resultatet av insticksprogrammet, som visar insticksprogrammets starka och svaga sidor. Alla bilderna nedan är gjorda med SketchyModel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flower_001_detail681×456 22.1 KB
{kind=link}

portrait_man_portrait_2_comparison_2_small1305×505 139 KB
{kind=link}

portrait_man_portrait_2_detail646×1023 26.6 KB
{kind=link}
Akka bilderna ovan målade av Tiar (länk till KA-profil)
På bilderna nedan, kan man kan se hur modellen urskiljer ljusare linjer och förstärker de starkare linjerna på fiskens fjäll, vilket gör fjällen mer uttalade. I teorin skulle man kunna göra det med hjälp av nivåfiltret, men i praktiken skulle resultaten bli sämre, eftersom modellen tar hänsyn till linjens lokala styrka.
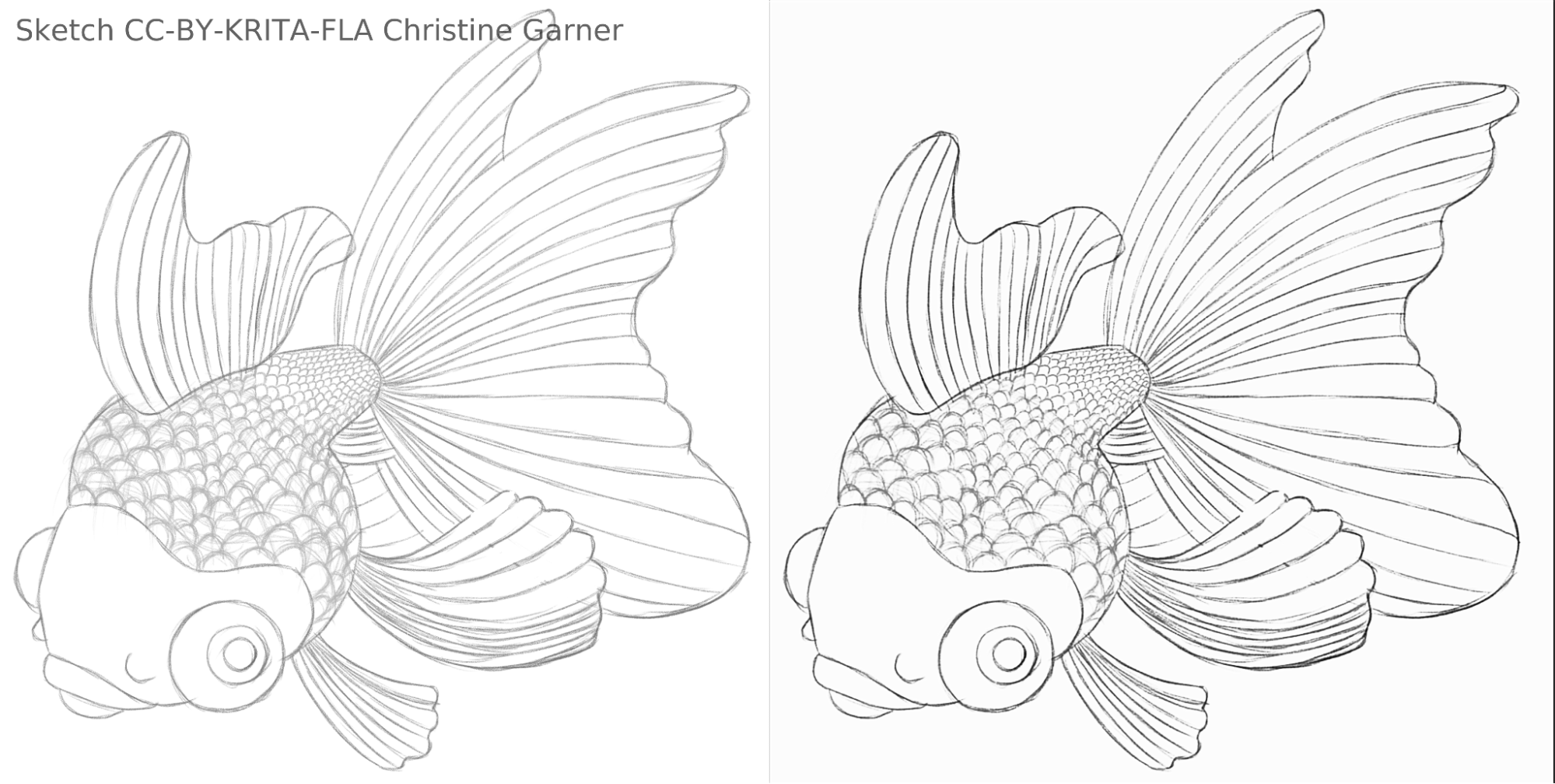
fish_square_sketchy_comparison_small1920×968 156 KB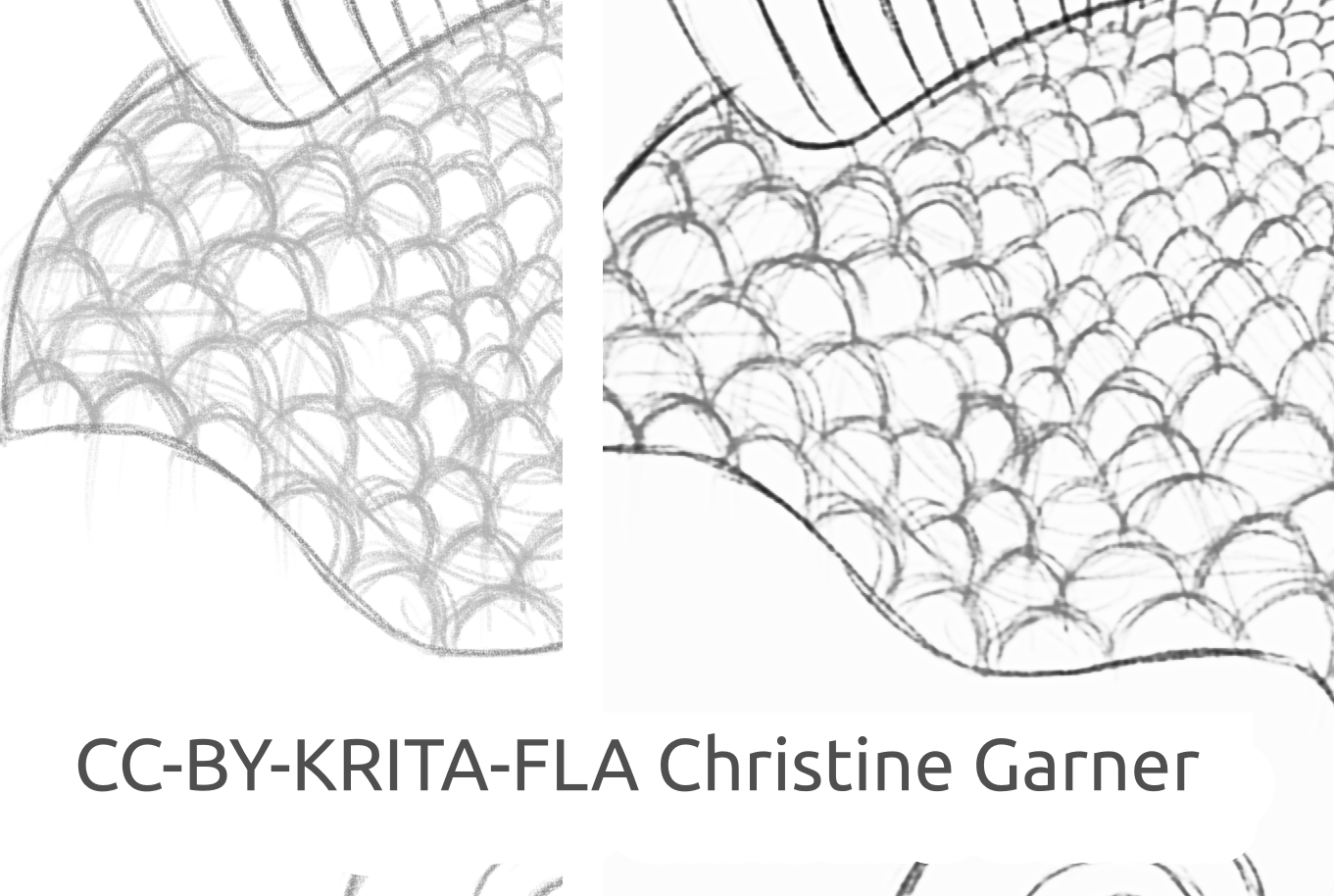
{kind=link}
Bild på fisken skapad av Christine Garner (länk till portfölj)
Hur man använder det i Krita
För att använda insticksprogrammet Snabb skissförbättring i Krita, gör följande:
- Förbered Krita
- På Windows:
- Antingen i ett paket: ladda ner Krita 5.3.0-prealpha med insticksprogrammet Snabb skissförbättring som redan ingår: [https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.zip](https://files.kde.org/ krita/testing/testing-ai-sketch-plugin/krita-x64-5.3.0-prealpha-ae1a4b69.zip)
- Eller separat:
- Ladda ner flyttbar version av Krita 5.2.6 (eller liknande version - borde fortfarande fungera)
- Ladda ner insticksprogrammet Snabb skissförbättring separat här: https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- Packa upp filen i krita-5.2.6/ katalogen (behåll katalogstrukturen).
- Gå sedan till Inställningar → Anpassa Krita → Python instickshanterare, aktivera insticksprogrammet Snabb skissförbättring, och starta om Krita.
- På Linux:
- Ladda ner appimage: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
- På Windows:
- (Valfritt) Installera NPU-drivrutiner om NPU finns på datorn (praktiskt taget bara nödvändigt på Linux, om den har en mycket ny Intel-processor): [Inställningar för Intel® NPU med OpenVINO™ — OpenVINO™-dokumentation](https://docs .openvino.ai/2024/get-started/configurations/configurations-intel-npu.html) (observera: det går ändå att köra insticksprogrammet på processorn eller grafikprocessorn, det kräver inte NPU)
- Kör insticksprogrammet
- Öppna eller skapa en vit duk med gråvita streck (observera att insticksprogrammet tar den aktuella projektionen av duken, inte det aktuella lagret).
- Gå till Verktyg → Snabb skissförbättring
- Välj modellen. Avancerade alternativ blir automatiskt valda.
- Vänta tills det är klart med behandlingen (dialogrutan stängs då automatiskt)
- Se att det skapade ett nytt lager med resultatet.
Råd om behandling
För närvarande är det bättre att bara använda SketchyModel.xml, i de flesta fall fungerar det betydligt bättre än SmoothModel.xml.
Man måste se till att bakgrunden är ganska ljus, och att linjerna som ska behållas i resultatet är relativt mörka (antingen något mörkgrå eller svarta; ljusgrå kan resultera i många missade linjer). Det kan vara en bra idé att använda ett filter som Nivåer i förväg.
Efter bearbetningen kanske man vill förbättra resultaten antingen med nivåfilter eller skärpefilter, beroende på resultatet.
Teknologi och vetenskap bakom det
Unika krav
Det första unika kravet var att det skulle fungera på dukar av alla storlekar. Det innebar att nätverket inte kunde ha några täta/helt eller tätt sammanbundna linjära lager som är mycket vanliga i de flesta av de neurala bildbehandlingsnätverken (som kräver indata av en specifik storlek och ger olika resultat för samma bildpunkt beroende på dess plats), bara konvolution eller ansamling eller liknande lager som ger samma resultat för varje bildpunkt på duken, oavsett plats. Lyckligtvis beskrev Simo & Sierra avhandlingen publicerad 2016 ett nätverk som just såg ut så.
En annan utmaning var att vi inte riktigt kunde använda modellen de skapade, eftersom den inte var kompatibel med Kritas licens, och vi kunde inte ens riktigt använda den exakta modelltypen de beskrev, eftersom en av dessa modellfiler skulle vara nästan lika stor som Krita, och träningen skulle ta riktigt lång tid. Vi behövde något som skulle fungera lika bra om inte bättre, men tillräckligt litet så att det kan läggas till i Krita utan att göra det dubbelt så stort. (I teorin skulle vi kunna göra som vissa andra företag och få bearbetningen att ske på någon sorts server, men det var inte vad vi ville. Och även om det löste några av våra problem, skulle det ge massor av egna stora problem Vi ville också att våra användare skulle kunna använda det lokalt utan att vara beroende av våra servrar och Internet). Dessutom måste modellen vara ganska snabb och även blygsam när det gäller minnes- och videominnesanvändning.
Dessutom hade vi ingen datauppsättning vi kunde använda. Simo & Sierra använde en datauppsättning där alla förväntade bilder ritades med konstant linjebredd och transparens, vilket innebar att resultaten av träningen också hade de egenskaperna. Vi ville ha något som såg lite mer handritat ut, med varierande linjebredd eller halvtransparenta linjeslut, så vår datauppsättning var tvungen att innehålla den typen av bilder. Eftersom vi inte kände till några datauppsättningar som skulle motsvara våra krav gällande licensen och datainsamlingsprocessen bad vi vår egen gemenskap om hjälp. Här kan du läsa tråden på Krita Artists om det: [https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401](https://krita-artists.org/t/ call-for-donation-of-artworks-for-the-fast-line-art-project/96401) .
Länken till hela vår datauppsättning finns nedan i datauppsättningsavsnittet.
Modellarkitektur
Alla huvudlager är antingen konvolutionella eller dekonvolutionella (i slutet av modellen). Efter varje (de)konvolutioella lager utom det sista finns ett ReLu-aktiveringslager, och efter den sista konvolutionen finns det ett sigmoid-aktiveringslager.
Använda Python-paket: Pillow, Numpy, PyTorch och Openvino
Numpy är ett standardbibliotek för alla typer av fält och avancerade fältoperationer och vi använde Pillow för att läsa bilder och konvertera dem till numpy-fält och tillbaka. För träning använde vi PyTorch, medan vi i Kritas insticksprogram använde Openvino för slutledning (bearbetning via nätverket).
Användning av NPU för slutledning

Tabellen visar resultatet av benchmark_app, som är ett verktyg som tillhandahålls med Intels Pythonpaket openvino. Det testar modellen isolerat på slumpmässiga data. Som man kan se var NPU flera gånger snabbare än processorn på samma maskin.
Å andra sidan, introduktionen av NPU gav en utmaning: de enda modellerna som kan köras på en NPU är statiska modeller, vilket betyder att inmatningsstorleken är känd när modellen sparas i en fil. För att lösa det delar insticksprogrammet först duken i mindre delar av en specificerad storlek (vilken beror på modellfilen), och fortsätter sedan med att bearbeta dem alla och syr slutligen ihop resultaten. För att undvika förvrängningar av områdena intill sammanfogningen delas alla med lite marginal och marginalen beskärs senare.
Hur man tränar sin egen modell
För att träna en egen modell behöver man några tekniska färdigheter, parvisa bilder (indata och förväntad utdata) och en kraftfull dator. Man kan också behöva ganska mycket utrymme på hårddisken, även om man bara kan ta bort onödiga äldre modeller om man börjar få utrymmesproblem.
Drivrutiner och förberedelser
Man måste installera Python3 och följande paket: Pillow, openvino, numpy, torch. För kvantisering av modellen behövs även nncf och sklearn. Om jag glömt något klagar den, så installera bara de paket som den nämner också.
Om man använder Windows har man förmodligen drivrutiner för NPU och dedikerad grafikprocessorer. På Linux kan man behöva installera NPU-drivrutiner innan man kan använda den: [https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html](https: //docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html).
Om man dessutom vill använda iGPU för träning (som fortfarande kan vara betydligt snabbare än på processorn), måste man förmodligen använda något som IPEX som tillåter PyTorch att använda en "XPU"-enhet, som bara är en iGPU. Det är inte testat eller rekommenderat eftersom jag personligen inte har kunnat använda det på grund av att min version av Python var senare än vad instruktionen förväntade sig, men instruktionen finns här: [https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu](https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10 %2Bxpu) .
Synlighetskontrollen för installationen är som följer:
python3 -c "import torch; import intel_extension_for_pytorch as ipex; print(f'Packages versions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Devices:'); print(f'Torch XPU device count: {torch.xpu.device_count()}'); [print(f'[Device {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
Det bör visa mer än 0 enheter med vissa grundläggande egenskaper.
Om man lyckas få XPU-enheten att fungera på datorn måste man ändå redigera träningsskripten så att de kan använda den: [https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html](https://intel.github.io/intel-extension-for-pytorch /xpu/latest/tutorials/getting_started.html) (förmodligen behöver man bara lägga till den här raden:
import intel_extension_for_pytorch as ipex
till skriptet längst upp, precis under "import torch", och använda "xpu" som enhetsnamn när skriptet anropas, så borde det fungera. Men skripten har som sagt inte testats för det.
Datauppsättning
Man behöver några bilder för att kunna träna modellen. Bilderna måste vara i par, varje par måste innehålla en skiss (indata) och en linjeteckningsbild (förväntad utdata). Ju bättre kvalitet på datauppsättningen, desto bättre resultat.
Innan träning är det bäst att utöka data: det betyder att bilderna roteras, skalas upp eller ned och speglas. För närvarande utför skriptet för datautökning också en inversion med antagandet att träning på inverterade bilder ger resultaten snabbare (med tanke på att svart betyder noll, vilket betyder ingen signal, och vi vill att det ska vara bakgrunden, så att modellerna lär sig linjerna, inte bakgrunden omkring linjerna).
Hur man använder skriptet för datautökning förklaras nedan i den detaljerade instruktionen om träningsdelen.
Här är datauppsättningen som vi använde (läs licensen noggrant om du vill använda den): https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
Val av modell och andra parametrar
För snabba resultat, använd tooSmallConv. Om man har mer tid och resurser kan typicalDeep vara en bättre idé. Om man har tillgång till en kraftfull grafikprocessor kan man prova original eller originalSmaller, som representerar den ursprungliga beskrivningen av modellen från [SIGGRAPH-artikeln av Simo-Sierra 2016](https://esslab.jp/~ess/publications/ SimoSerraSIGGRAPH2016.pdf), och en mindre version av den.
Använd adadelta som optimeringsverktyg.
Man kan använda antingen blackWhite eller mse som förlustfunktion. mse är klassisk, men blackWhite kan leda till snabbare resultat eftersom det minskar det relativa felet på de helt vita eller helt svarta områdena (baserat på den förväntade utdatabilden).
Träning
Kopiera arkivet på https://invent.kde.org/tymond/fast-line-art (at 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.gitFörbered sedan katalogen:
- Skapa en ny katalog för träning.
- I katalogen, kör:
python3 [arkivkatalog]/spawnExperiment.py --path [sökväg till ny katalog, antingen relativ eller absolut] --note "[personlig anmärkning om experimentet]"
Förbered data:
- Om en befintlig utökad datauppsättning finns, lägg in allt i data/training/ och data/verify/, tänk på att samhörande bilder i underkatalogerna ink/ och sketch/ måste ha exakt samma namn (till exempel om man har sketch.png och ink.png som data, måste en placeras i sketch/ som bild.png och den andra i ink/ som bild.png för att paras ihop).
- Om en befintlig utökad datauppsättning inte finns:
- Lägg all obehandlad data i data/raw/, tänk på att samhörande bilder ska ha exakt samma namn med tillagt prefix antingen ink_ eller sketch_ (till exempel om man har bild_1.png som skissbild och bild_2.png är den andra bilden, måste de ges namnet sketch_bild.png respektive ink_bild.png.)
- Kör dataförberedelseskriptet:
python3 [arkivkatalog]/dataPreparer.py -t taskfile.yml
Det utökar data i den obehandlade katalogen för att träningen ska bli framgångsrikare.
Redigera filen taskfile.yml efter behov. De viktigaste delarna som man kan vilja ändra är:
- model type - kodnamn för modelltypen, använd tinyTinier, tooSmallConv, typicalDeep eller tinyNarrowerShallow
- optimizer - typ av optimeringsverktyg, använd adadelta eller sgd
- learning rate - Inlärningshastighet för sgd om det används
- loss function - kodnamn för förlustfunktion, använd mse för medelkvadratfel eller blackWhite för en anpassad förlustfunktion baserad på mse, men lite mindre för bildpunkter där målbildens bildpunktsvärde är nära 0,5
Kör träningskoden:
python3 [arkivkatalog]/train.py -t taskfile.yml -d "cpu"På Linux, om man vill att den ska köras i bakgrunden, lägg till "&" i slutet. Om den körs i förgrunden kan man pausa träningen bara genom att trycka på ctrl+C, och om den körs i bakgrunden, hitta process-id (med antingen kommandot "jobs -l" eller kommandot "ps aux | grep train. py”, är det första numret process-id) och döda det med kommandot “kill [process id]”. Resultaten finns fortfarande i katalogen och man kan återuppta träningen med samma kommando.
Konvertera modellen till en openvino-modell:
python3 [arkivkatalog]/modelConverter.py -s [storlek på indata, rekommenderad 256] -t [modellnamn, från pytorch] -o [openvino modellnamn, måste sluta med .xml]Placera både .xml- och .bin-modellfilerna i Kritas resurskatalog (i underkatalogen pykrita/fast_sketch_cleanup) bredvid andra modeller för att använda dem i insticksprogrammet.