Explorando o plugin de Limpeza rápida de esboços para Krita
Plugin de Limpeza rápida de esboços
Introdução
Iniciamos este projeto com a intenção de fornecer aos usuários uma ferramenta útil para traçar esboços. Ele se baseia em um artigo de pesquisa de Simo & Sierra publicado em 2016 e utiliza redes neurais (hoje comumente chamadas simplesmente de IA) para funcionar. A ferramenta foi desenvolvida em parceria com a Intel e ainda é considerada experimental, mas você já pode usá-la e ver os resultados.
Na seção abaixo, você encontrará alguns exemplos reais de casos de uso e os resultados do plugin. Os resultados variam, mas ele pode ser usado para extrair esboços a lápis de fotos, limpar linhas e fazer arte-final de histórias em quadrinhos.
Em relação ao modelo usado na ferramenta, nós mesmos o treinamos. Todos os dados do conjunto de dados foram doados por pessoas que nos enviaram suas fotos e concordaram com este caso de uso específico. Não utilizamos nenhum outro dado. Além disso, quando você usa o plugin, ele processa localmente na sua máquina, não requer conexão com a internet, não se conecta a nenhum servidor e também não é necessária nenhuma conta. Atualmente, ele funciona apenas no Windows e no Linux, mas trabalharemos para disponibilizá-lo também no macOS.
Casos de uso
Ele calcula a média das linhas em uma única linha e cria linhas pretas fortes, mas o resultado final pode ser borrado ou irregular. Em muitos casos, porém, ainda funciona melhor do que usar apenas um filtro de Níveis (por exemplo, ao extrair o esboço a lápis). Pode ser uma boa ideia usar o filtro de Níveis após usar o plugin para reduzir o desfoque. Como o plugin funciona melhor com telas brancas e linhas cinza-escuras, no caso de esboços a lápis fotografados ou linhas de esboço muito claras, pode ser uma boa ideia usar os Níveis também antes de usar o plugin.
Extraindo esboço a lápis fotografado
Este é o resultado do procedimento padrão de usar o filtro Níveis em um esboço para extrair as linhas (o que resulta em uma parte da imagem recebendo a sombra):

esboço_garota_original_procedimento_comparação_pequeno1843×1209 165 KB
O esboço foi desenhado por Tiar (link para o perfil do KA)
Este é o procedimento usando o plugin com modelo de esboço (Níveis → plugin → Níveis):

esboço_garota_novo_procedimento_comparação_pequeno1843×2419 267 KB
Comparação (para linhas pretas):

esboço_garota_novo_procedimento_comparação\pequeno1920×1260 215 KB
Outro resultado possível é simplesmente parar no plugin sem forçar linhas pretas usando Níveis, o que resulta em uma aparência mais agradável, mais parecida com lápis, enquanto mantém a parte inferior da página ainda em branco:

rascunho_garota_após_plugin_pequeno1536×2016 161 KB
Tinta tipo história em quadrinhos
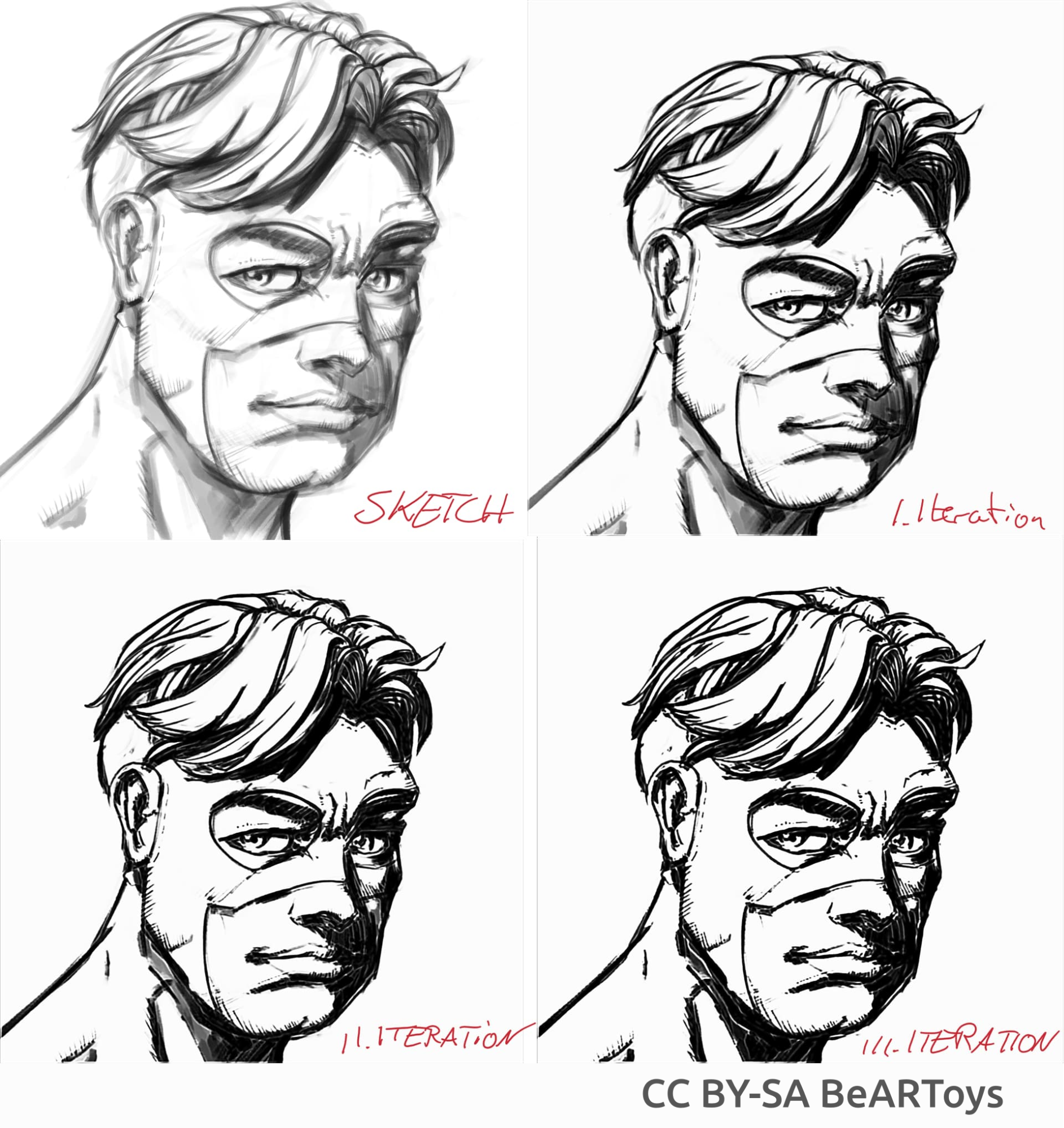
Imagem de um homem feita por BeARToys

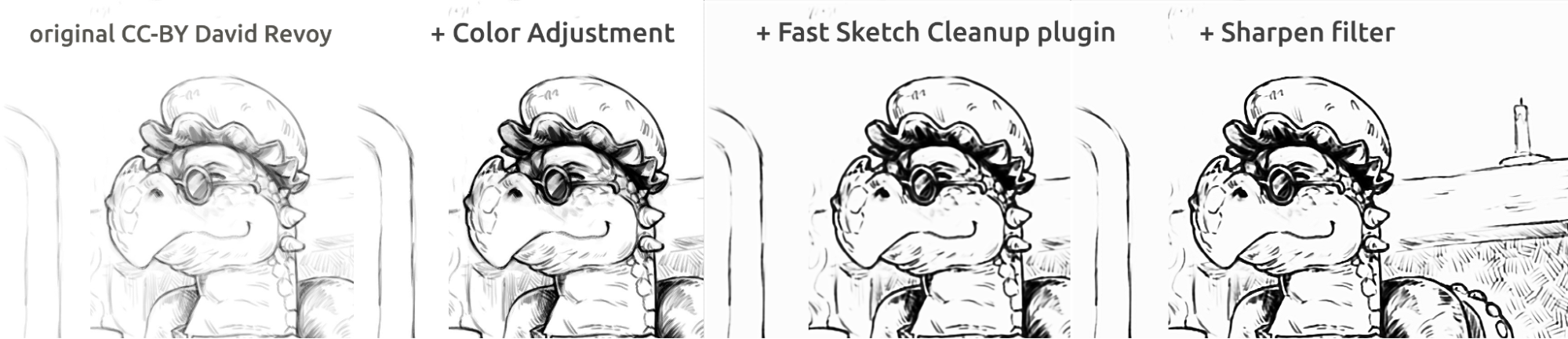
Aqui nas fotos acima, você pode ver a arte-final no estilo de história em quadrinhos. O resultado, que é um pouco borrado em comparação com o original, pode ser ainda mais aprimorado usando um filtro de nitidez. O dragão foi esboçado por David Revoy (CC-BY 4.0).
Limpando as linhas
Exemplos dos esboços que fiz e o resultado do plugin, mostrando os pontos fortes e fracos do plugin. Todas as imagens abaixo foram feitas usando o SketchyModel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flor_001_detail681×456 22.1 KB
{kind=link}

retrato_homem_retrato_2_comparação_2_pequeno1305×505 139 KB
{kind=link}

retrato_homem_retrato_2_detalhe646×1023 26.6 KB
{kind=link}
Todas as imagens acima foram pintadas por Tiar (link para o perfil do KA)
Nas imagens abaixo, nas escamas dos peixes, você pode ver como o modelo discrimina linhas mais claras e realça as linhas mais fortes, tornando as escamas mais pronunciadas. Em teoria, você poderia fazer isso usando o filtro Níveis, mas na prática os resultados seriam piores, porque o modelo leva em consideração a força local da linha.
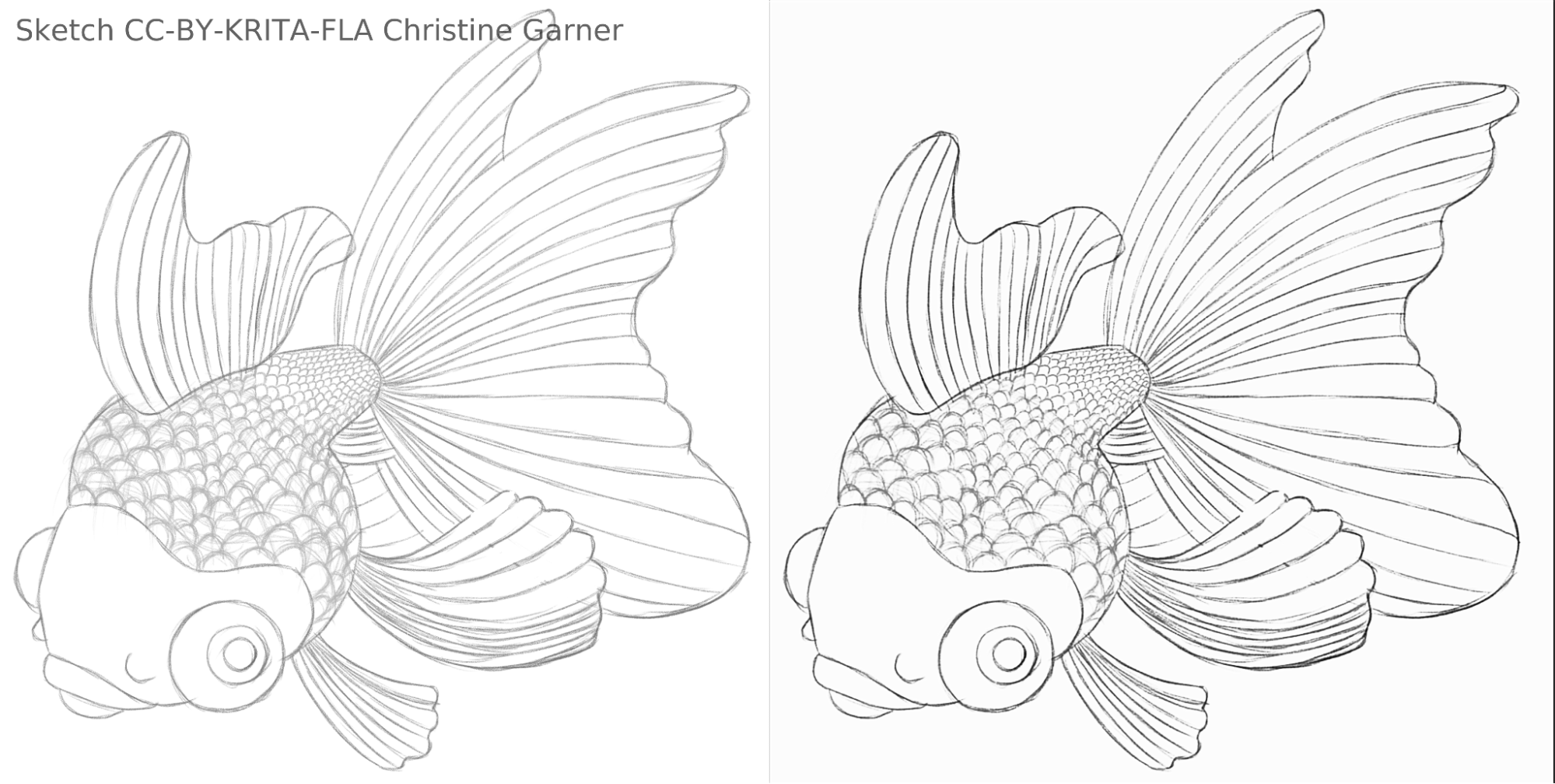
peixe_quadrado_rascunho_comparação_pequeno1920×968 156 KB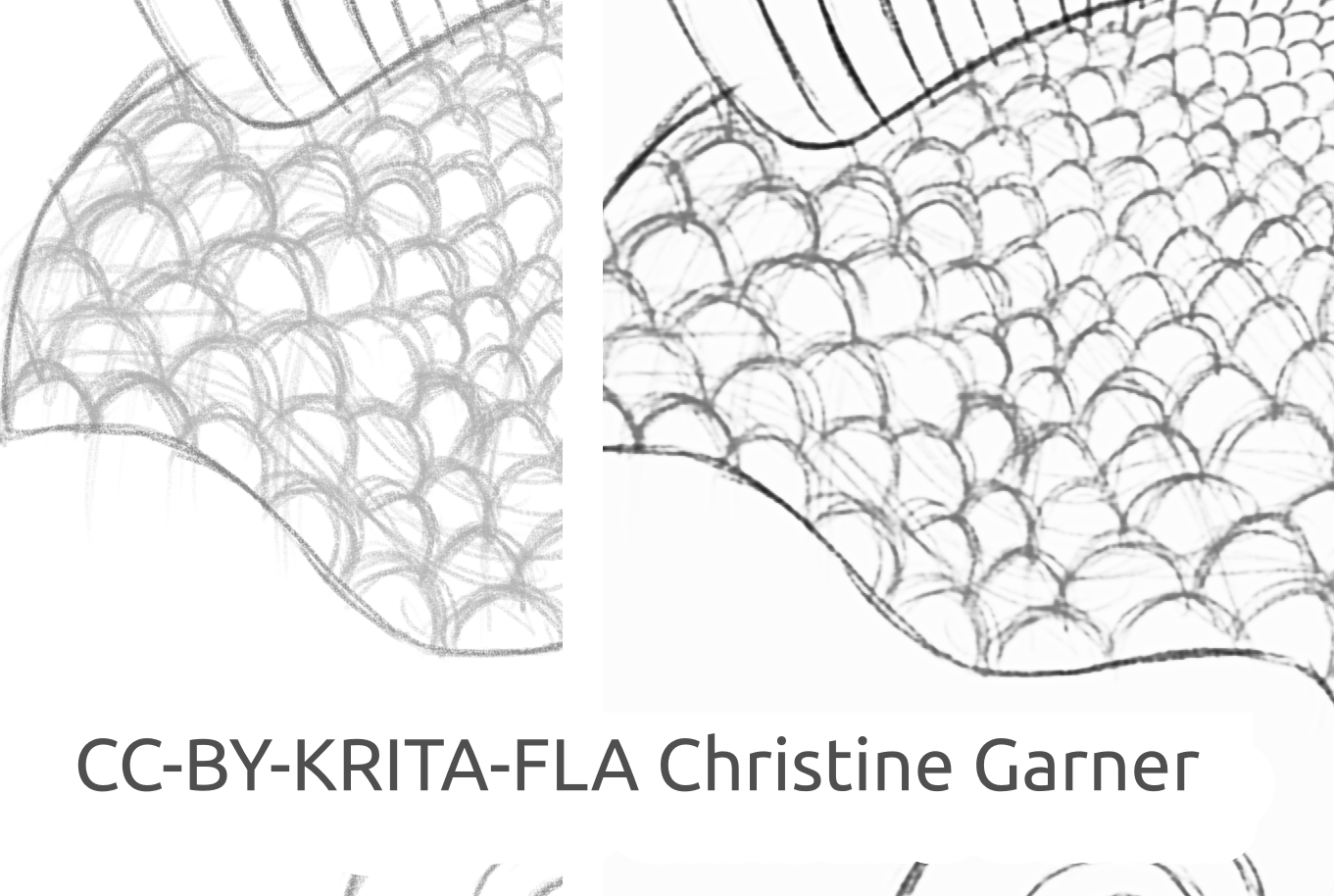
{kind=link}
Imagem do peixe feita por Christine Garner (link para o portfólio)
Como usá-lo no Krita
Para usar o plugin de limpeza rápida de esboços no Krita, faça o seguinte:
- Prepare o Krita:
- No Windows:
- Em um único pacote: baixe o Krita 5.3.0-prealpha com plugin de limpeza rápida de esboços já incluído: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.zip
- Ou separadamente:
- Baixe a versão portátil do Krita 5.2.6 (ou versão similar - ainda deve funcionar)
- Baixe separadamente o plugin de limpeza rápida de esboços aqui: https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- Descompacte o arquivo na pasta do krita-5.2.6/ (mantendo a estrutura da pasta).
- Em seguida, vá para Configurações → Configurar Krita → Gerenciador de plugins Python, ative o plugin de limpeza rápida de esboço e reinicie o Krita.
- No Linux:
- Baixe a imagem do aplicativo: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
- No Windows:
- (Opcional) Instale os drivers NPU se você tiver NPU no seu dispositivo (praticamente necessário apenas no Linux, se você tiver uma CPU Intel muito nova): Configurações para Intel® NPU com OpenVINO™ — documentação do OpenVINO™(observação: você ainda pode executar o plugin na CPU ou GPU, pois ele não requer NPU)
- Execute o plugin:
- Abra ou crie uma tela branca com traços cinza-esbranquiçados (observe que o plugin usará a projeção atual da tela, não a camada atual).
- Vá para Ferramentas → Limpeza rápida de esboços
- Selecione o modelo. As opções avançadas serão selecionadas automaticamente para você.
- Aguarde até que o processamento seja concluído (a caixa de diálogo será fechada automaticamente).
- Veja que foi criada uma nova camada com o resultado.
Conselhos para processamento
Atualmente, é melhor usar apenas o SketchyModel.xml; na maioria dos casos, ele funciona significativamente melhor que o SmoothModel.xml.
Você precisa garantir que o fundo esteja bem claro e que as linhas que você deseja manter no resultado sejam relativamente escuras (cinza um pouco escuro ou preto; cinza claro pode resultar em muitas linhas faltando). Pode ser uma boa ideia usar um filtro como Níveis antes.
Após o processamento, você pode querer aprimorar os resultados com o filtro Níveis ou Nitidez, dependendo dos seus resultados.
Tecnologia e ciência por trás disso
Requisitos exclusivos
O primeiro requisito exclusivo era que ele funcionasse em telas de todos os tamanhos. Isso significava que a rede não poderia ter nenhuma camada linear densa/totalmente ou densamente conectada, que são muito comuns na maioria das redes neurais de processamento de imagens (que exigem entrada de um tamanho específico e produzirão resultados diferentes para o mesmo pixel, dependendo de sua localização), apenas convoluções, agrupamentos ou camadas semelhantes que produzissem os mesmos resultados para cada pixel da tela, independentemente da localização. Felizmente, o artigo de Simo & Sierra publicado em 2016 descreveu uma rede exatamente assim.
Outro desafio era que não podíamos usar o modelo que eles criaram, já que não era compatível com a licença do Krita, e nem mesmo usar o tipo exato de modelo que eles descreveram, porque um desses arquivos de modelo seria quase tão grande quanto o do Krita, e o treinamento levaria muito tempo. Precisávamos de algo que funcionasse tão bem quanto, se não melhor, mas pequeno o suficiente para ser adicionado ao Krita sem torná-lo duas vezes maior. (Em teoria, poderíamos fazer como algumas outras empresas e fazer o processamento acontecer em algum tipo de servidor, mas não era isso que queríamos. E mesmo que resolvesse alguns dos nossos problemas, ainda traria muitos dos seus principais desafios. Além disso, queríamos que nossos usuários pudessem usá-lo localmente sem depender de nossos servidores e da internet). Além disso, o modelo tinha que ser razoavelmente rápido e também modesto em relação ao consumo de RAM/VRAM.
Além disso, não tínhamos nenhum conjunto de dados que pudéssemos usar. Simo & Sierra usaram um conjunto de dados em que as imagens esperadas foram todas desenhadas usando uma largura de linha e transparência constantes, o que significava que os resultados do treinamento também tinham essas qualidades. Queríamos algo que parecesse um pouco mais desenhado à mão, com larguras de linha variáveis ou extremidades semitransparentes das linhas, então nosso conjunto de dados precisava conter esses tipos de imagens. Como não tínhamos conhecimento de nenhum conjunto de dados que atendesse aos nossos requisitos em relação à licença e ao processo de coleta de dados, pedimos ajuda à nossa própria comunidade. Aqui você pode ler o tópico do Krita Artists sobre isso: https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401.
O link para nosso conjunto de dados completo pode ser encontrado abaixo na seção Conjunto de dados.
Arquitetura modelo
Todas as camadas principais são convolucionais ou deconvolucionais (no final do modelo). Após cada camada (de)convolucional, exceto a última, há uma camada de ativação ReLu, e após a última convolução, há uma camada de ativação sigmoide.
Pacotes Python usados: Pillow, Numpy, PyTorch e Openvino
Numpy é uma biblioteca padrão para todos os tipos de matrizes e operações avançadas de matrizes, e usamos o Pillow para ler imagens e convertê-las em matrizes numpy e vice-versa. Para treinamento, usamos o PyTorch, enquanto no plugin do Krita, usamos o Openvino para inferência (processamento pela rede).
Usando NPU para inferência

Esta tabela mostra o resultado do benchmark_app, uma ferramenta fornecida com o pacote python openvino da Intel. Ela testa o modelo isoladamente em dados aleatórios. Como você pode ver, a NPU foi várias vezes mais rápida que a CPU na mesma máquina.
Por outro lado, a introdução do NPU acrescentou um desafio: os únicos modelos que podem ser executados no NPU são modelos estáticos, o que significa que o tamanho da entrada é conhecido no momento em que o modelo é salvo no arquivo. Para resolver isso, o plugin primeiro corta a tela em partes menores de um tamanho especificado (que depende do arquivo do modelo) e, em seguida, processa todas elas e, por fim, costura os resultados. Para evitar artefatos nas áreas próximas à costura, todas as partes são cortadas com uma pequena margem, que é posteriormente cortada.
Como treinar seu próprio modelo
Para treinar seu próprio modelo, você precisará de algumas habilidades técnicas, pares de imagens (entrada e saída esperada) e um computador potente. Você também pode precisar de bastante espaço no seu disco rígido, embora possa simplesmente remover modelos antigos desnecessários se começar a ter problemas com falta de espaço.
Drivers & preparação
Você precisará instalar o Python3 e os seguintes pacotes: Pillow, openvino, numpy, torch. Para a quantização do modelo, você também precisará do nncf e do sklearn. Se eu esqueci de alguma coisa, ele vai reclamar, então instale também os pacotes mencionados.
Se você usa Windows, provavelmente tem drivers para NPU e GPU dedicada. No Linux, pode ser necessário instalar os drivers da NPU antes de poder usá-lo: https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html .
Além disso, se você quiser usar iGPU para treinamento (que ainda pode ser significativamente mais rápido do que na CPU), provavelmente precisará usar algo como IPEX, que permite que o PyTorch use um dispositivo "XPU", que é apenas sua iGPU. Não foi testado nem recomendado, pois eu pessoalmente não consegui usá-lo porque minha versão do Python era superior à esperada pela instrução, mas a instrução está aqui: https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu .
A verificação de integridade da instalação é a seguinte:
python3 -c "import torch;import intel_extension_for_pytorch as ipex; print(f'Packagesversions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Dispositivos:'); print(f'Contagem de dispositivos Torch XPU: {torch.xpu.device_count()}'); [print(f'[Dispositivo {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
Deve mostrar mais de 0 dispositivos com algumas propriedades básicas.
Se você conseguir fazer o dispositivo XPU funcionar na sua máquina, ainda precisará editar os scripts de treinamento para que eles possam usá-lo: https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html (provavelmente você só precisará adicionar esta linha:
import intel_extensão_para_pytorch as ipex
ao script no topo, logo abaixo de "import torch", e usar "xpu" como nome do dispositivo ao invocar o script, e ele deverá funcionar. Mas, como eu disse, os scripts não foram testados para isso.
Conjunto de dados
Você precisará de algumas imagens para treinar seu modelo. As imagens devem estar em pares, cada par deve conter um esboço (entrada) e uma imagem lineart (saída esperada). Quanto melhor a qualidade do conjunto de dados, melhores serão os resultados.
Antes do treinamento, é melhor aumentar os dados: isso significa que as imagens são rotacionadas, ampliadas ou reduzidas e espelhadas. Atualmente, o script de aumento de dados também realiza uma inversão, partindo do princípio de que o treinamento em imagens invertidas traria os resultados mais rapidamente (considerando que preto significa zero, ou seja, sem sinal, e gostaríamos que esse fosse o fundo, para que os modelos aprendam as linhas, não o fundo ao redor das linhas).
Como usar o script de aumento de dados é explicado abaixo nas instruções detalhadas da parte de treinamento.
Aqui está o conjunto de dados que usamos (leia a licença com atenção se quiser usá-lo): https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
Escolha do modelo e outros parâmetros
Para resultados rápidos, use tooSmallConv; se você tiver mais tempo e recursos, typicalDeep pode ser uma ideia melhor. Se você tiver acesso a uma máquina com GPU potente, pode tentar original ou originalSmaller, que representam a descrição original do modelo do artigo SIGGRAPH de Simo-Sierra de 2016 e uma versão menor dele.
Use adadelta como otimizador.
Você pode usar blackWhite ou mse como função de perda; mse é clássico, mas blackWhite pode levar a resultados mais rápidos, pois reduz o erro relativo nas áreas totalmente brancas ou totalmente pretas (com base na imagem de saída esperada).
Treinamento
Clone o repositório em https://invent.kde.org/tymond/fast-line-art (em 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.gitEm seguida, prepare a pasta:
- Crie uma nova pasta para o treinamento.
- Na pasta, execute:
python3 [pasta do repositório]/spawnExperiment.py --path [caminho para a nova pasta, relativo ou absoluto] --note "[sua observação pessoal sobre o experimento]"
Prepare os dados:
- Se você já tiver um conjunto de dados aumentado, coloque tudo em data/training/ e data/verify/, tendo em mente que as imagens pareadas nas subpastas ink/ e sketch/ devem ter exatamente os mesmos nomes (por exemplo, se você tiver sketch.png e ink.png como data, precisará colocar uma em sketch/ como picture.png eoutra em ink/ como picture.png para parear).
- Se você não tiver um conjunto de dados aumentado existente:
- Coloque todos os seus dados brutos em data/raw/, tendo em mente que as imagens pareadas devem ter exatamente os mesmos nomes, com o prefixo ink_ ou sketch_ (por exemplo, se você tiver picture_1.png sendo a imagem do esboço e picture_2.png sendo a imagem da tinta, você precisa nomeá-las sketch_picture.png e ink_picture.png respectivamente.)
- Execute o script do preparador de dados:
python3 [pasta do repositório]/dataPreparer.py -t taskfile.yml
Isso aumentará os dados no diretório bruto para que o treinamento seja mais bem-sucedido.
Edite o arquivo taskfile.yml como preferir. As partes mais importantes que você deseja alterar são:
- model type- nome do código para o tipo de modelo, use tinyTinier, tooSmallConv, typicalDeep ou tinyNarrowerShallow
- optimizer - tipo de otimizador, use adadelta ou sgd
- learning rate - taxa de aprendizagem para sgd se em uso
- loss function - codinome para função de perda, use mse para erro quadrático médio ou blackWhite para uma função de perda personalizada baseada em mse, mas um pouco menor para pixels onde o valor do pixel da imagem alvo é próximo de 0,5
Execute o código de treinamento:
python3 [pasta do repositório]/train.py -t taskfile.yml -d "cpu"No Linux, se você quiser que ele seja executado em segundo plano, adicione "&" no final. Se estiver em primeiro plano, você pode pausar o treinamento pressionando Ctrl+C. E se estiver em segundo plano, encontre um ID de processo (usando o comando "jobs -l" ou o comando "ps aux | grep train.py", o primeiro número seria o ID do processo) e finalize-o usando o comando "kill [ID do processo]". Seus resultados ainda estarão na pasta e você poderá retomar o treinamento usando o mesmo comando.
Converta o modelo para um modelo OpenVino:
python3 [pasta do repositório]/modelConverter.py -s [tamanho da entrada, recomendado 256] -t [nome do modelo de entrada, do PyTorch] -o [nome do modelo OpenVino, deve terminar com .xml]Coloque os arquivos de modelo .xml e .bin na sua pasta de recursos do Krita (dentro da subpasta pykrita/fast_sketch_cleanup) junto com outros modelos para usá-los no plugin.