Graven in de plug-in Snelle schets opschonen voor Krita
Plug-in Snelle schets opschonen
Inleiding
We zijn dit project gestart met de bedoeling gebruikers te voorzien van een hulpmiddel dat helpt bij het inkten van schetsen. Het is gebaseerd op een onderzoeksartikel door Simo & Sierra gepubliceerd in 2016 en het gebruikt neurale netwerken (nu algemeen eenvoudig AI genoemd) om te werken. Het hulpmiddel is ontwikkeld met Intel als partner en het wordt nog steeds als experimenteel beschouwd, maar u kunt het al gebruiken en de resultaten zien.
In de onderstaande sectie zijn enige echte voorbeelden van gebruiksgevallen en de resultaten van de plug-in. De resultaten variëren, maar het kan gebruikt worden voor extraheren van vage potloodschetsen uit foto's, lijnen opschonen en inkten van stripboeken.
Met betrekking tot het model gebruikt in het hulpmiddel, we hebben het zelf getraind. Alle gegevens in de dataset zijn gedoneerd door mensen die hun plaatjes zelf naar ons hebben gestuurd en toegestemd in dit specifieke gebruiksgeval. We hebben het geen enkele ander gegevens gebruikt. Bovendien, wanneer u de plug-in gebruikt, het werkt lokaal op uw machine, het vereist geen internetverbinding, maakt geen verbinding met een server en er is ook geen account vereist. Op dit moment werkt het alleen op Windows en Linux, maar we zullen er aan werken om het ook beschikbaar te maken op MacOS.
Voorbeelden van gebruik
Het middelt de lijnen in één lijn en maakt dikke zwarte lijnen, maar het eindresultaat kan wazig of ongelijk zijn. In veel gevallen echter werkt het nog steeds beter dan gewoon een Niveausfilter te gebruiken (bijvoorbeeld bij extraheren van de potloodschets). Het kan een goed idee zijn om Niveausfilter te gebruiken na gebruik van de plug-in om de wazigheid te verminderen. Omdat de plug-in het beste werkt met een wit werkveld en grijs-zwarte lijnen, in het geval van gefotografeerde potloodschetsen of erg licht geschetste lijnen, kan het een goed idee zijn om Niveaus ook te gebruiken voor het gebruik van de plug-in.
Extraheren van gefotografeerde potloodschets
Dit is het resultaat van de standaard procedure van gebruik van Niveaufilter op een schets om de lijnen te extraheren (wat resulteert in een gedeelte van de afbeelding die schaduw krijgt):

sketch_girl_original_procedure_comparison_small1843×1209 165 KB
De schets was getekend door Tiar (link to KA profile)
Dit is de procedure met gebruik van de plug-in met SketchyModel (Niveaus → plugin → Niveaus):

sketch_girl_new_procedure_comparison_small1843×2419 267 KB
Vergelijking (voor zwarte lijnen):

sketch_girl_procedures_comparison_small1920×1260 215 KB
Een ander mogelijk resultaat is om gewoon te stoppen bij de plug-in zonder zwarte lijnen af te dwingen met gebruik van Niveaus, wat resulteert in een mooiere, meer potloodachtig uiterlijk en het lagere deel van de pagina nog steeds blank:

sketch_girl_after_plugin_small1536×2016 161 KB
Stripboekachtig inkten
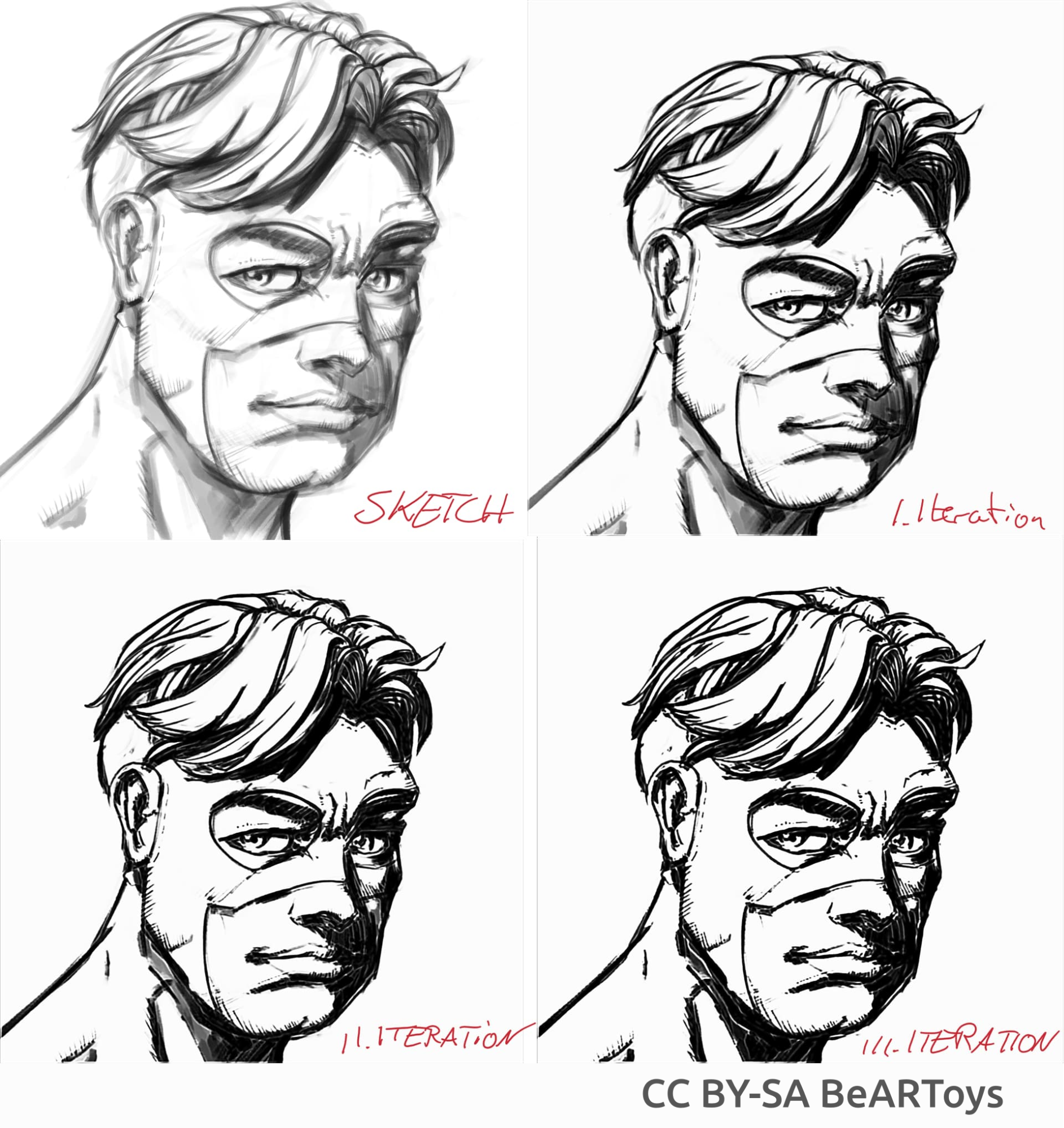
Plaatje van een man gemaakt door BeARToys

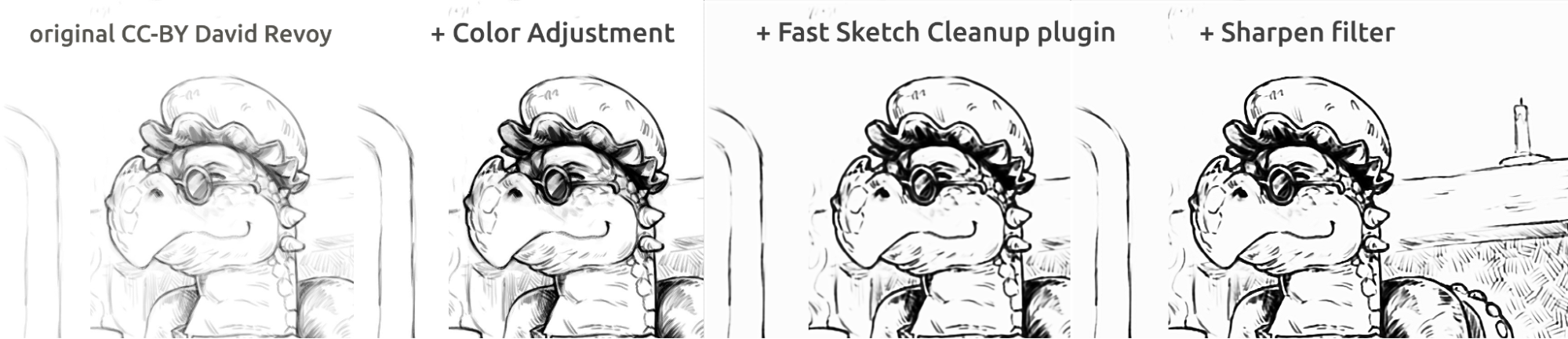
Hier in de bovenstaande plaatjes kunt u de stripboekstijl van inkten zien. Het resultaat, dat een beetje waziger is vergeleken met het origineel, kan verder verbeterd worden door een verscherpingsfilter. De draak is geschetst door David Revoy (CC-BY 4.0).
Lijnen worden opgeschoond
Voorbeelden van schetsen die ik maakte en het resultaat van de plug-in, die de sterke en zwakke punten van de plug-in laat zien. Alle onderstaande afbeeldingen zijn gemaakt met het SketchyModel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flower_001_detail681×456 22.1 KB
{kind=link}

portrait_man_portrait_2_comparison_2_small1305×505 139 KB
{kind=link}

portrait_man_portrait_2_detail646×1023 26.6 KB
{kind=link}
Alle bovenstaande plaatjes geschilderd door Tiar (koppeling naar KA profielen)
Op de onderstaande plaatjes, op de schubben van de vis, kunt u zien hoe het model lichtere lijnen discrimineert en dikkere lijnen verhoogt, waarmee de schubben meer uitgesproken worden. In theorie zou u dat kunnen doen met het Niveausfilter, maar in de praktijk zou het resultaat slechter kunnen zijn, omdat het model rekening houdt met de lokale dikte van de lijn.
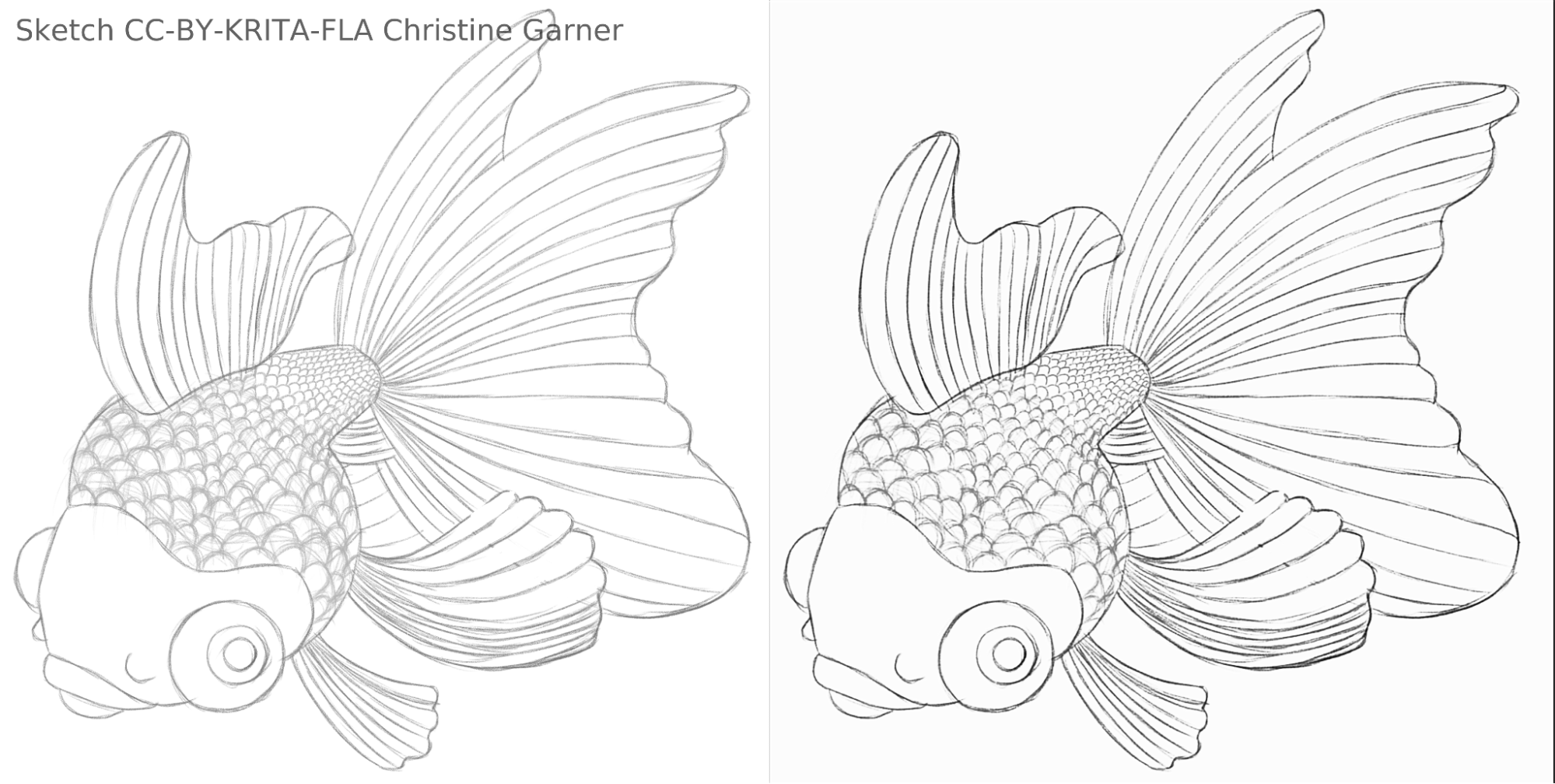
fish_square_sketchy_comparison_small1920×968 156 KB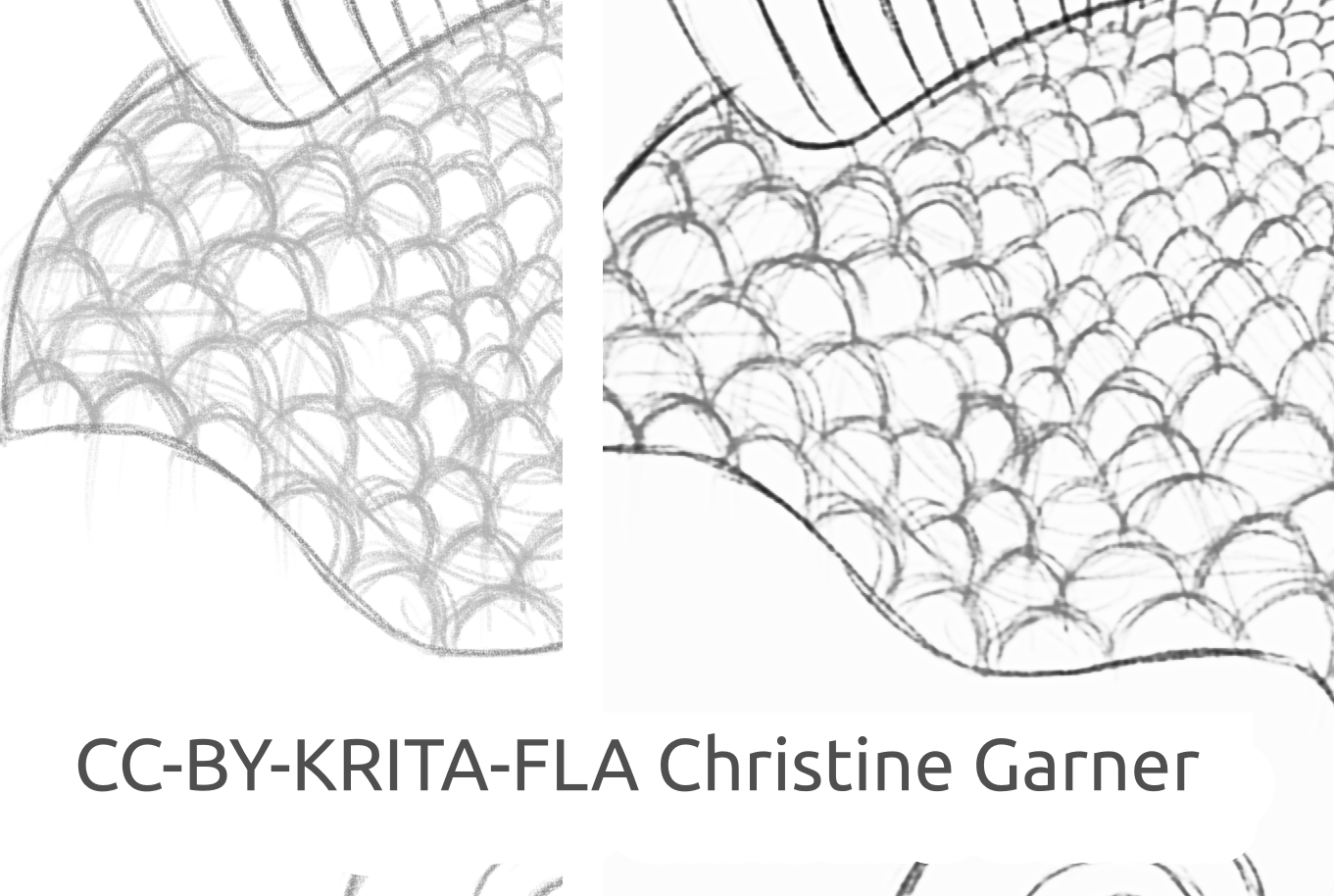
{kind=link}
Plaatje van de vis gemaakt door Christine Garner (link to portfolio)
Hoe het in Krita te gebruiken
Om de plug-in Snelle schets opschonen in Krita te gebruiken, doe het volgende:
- Krita voorbereiden:
- Op Windows:
- Ofwel in een pakket: download Krita 5.3.0-prealpha met de plug-in Snelle schets opschonen al meegeleverd: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.zip
- Of afzonderlijk:
- Download de overdraagbare versie van Krita 5.2.6 (of gelijkwaardige versie - zou nog steeds moeten werken)
- Download gescheiden de plug-in Snelle schets opschonen hier: https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- Unzip het bestand in map krita-5.2.6/ (met behoud van de mapstructuur).
- Ga daarna naar Instellingen → Krita configureren → Plug-inbeheerder van Python, plug-in Snelle schets opschonen en Krita opnieuw starten.
- Op Linux:
- Download de toepassingsimage: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
- Op Windows:
- (Optioneel) Installeer NPU-apparaatstuurprogramma's als u NPU hebt op uw apparaat (praktisch alleen nodig op Linux, als u een erg nieuwe Intel CPU hebt): Configuraties voor Intel® NPU met OpenVINO™ — OpenVINO™ documentatie (noot: u kunt nog steeds de plug-in op CPU of GPU uitvoeren, het vereist geen NPU)
- De plug-in uitvoeren:
- Open of maak een wit werkveld met grijs-witte stroken (merk op dat de plug-in de huidige projectie van het werkveld gebruikt, niet de huidige laag).
- Ga naar Hulpmiddelen → Snelle schets opschonen
- Selecteer het model. Geavanceerde opties zullen automatisch voor u geselecteerd worden.
- Wacht totdat het eindigt met verwerken (de dialoog zal dan automatisch sluiten).
- Zie dat het een nieuwe laag met het resultaat heeft gemaakt.
Advies voor verwerken
Op dit moment is het beter om gewoon de SketchyModel.xml te gebruiken, in de meeste gevallen werkt het aanzienlijk beter dan de SmoothModel.xml.
U moet er voor zorgen dat de achtergrond behoorlijk helder is en de lijnen die u wilt behouden in het resultaat relatief donker zijn (ofwel ietwat donker grijs of zwart; licht grijs kan resulteren in veel gemiste lijnen). Het kan een goed idee zijn om een filter zoals Niveaus van tevoren te gebruiken.
Na verwerken zou de resultaten willen verbeteren met ofwel filter Niveaus of filter Verscherpen, afhankelijk van uw resultaten.
Technologie & wetenschap erachter
Unieke vereisten
Het eerste unieke vereiste was dat het moet werken op werkvelden van alle groottes. Dat betekent dat het netwerk geen enkele dichte/volle of dicht verbonden lineaire lagen mag hebben die erg algemeen zijn in de meest van de neurale netwerken die afbeeldingen verwerken (wat vereist dat invoer van een specifieke grootte en verschillende resultaten zal produceren voor hetzelfde pixel afhankelijk van zijn locatie), alleen convoluties of pooling of gelijkwaardige lagen die dezelfde resultaten aan het produceren zijn voor elk pixel van het werkveld, ongeacht de locatie. Gelukkig, het paper Simo & Sierra gepubliceerd in 2016 beschrijft een netwerk net als dat.
Een andere uitdaging was dat we niet echt het model dat ze maakten konden gebruiken, omdat het niet compatibel was met de licentie van Krita en we konden zelfs niet echt het exacte modeltype gebruiken dat ze beschreven, omdat een van die modelbestanden bijna net zo groot zou zijn als Krita en de training zou werkelijk lang duren. We hadden iets nodig dat evengoed zou werken indien niet beter, maar klein genoeg dat het toegevoegd kan worden aan Krita zonder het tweemaal zo groot te maken. (In theorie zouden we kunnen doen zoals sommige andere bedrijven en de verwerking laten gebeuren op een soort server, maar dat was niet wat we wilden. En zelfs als het sommige van onze problemen zou oplossen, het zou veel van zijn eigen belangrijke uitdagingen leveren. We wilden ook voor onze gebruikers dat ze in staat zouden zijn het lokaal te gebruiken zonder afhankelijkheid van onze servers en het internet). Bovendien zou het model redelijk snel moeten zijn en ook bescheiden met betrekking tot gebruik van RAM/VRAM.
Bovendien hadden we geen enkele gegevensset die we konden gebruiken. Simo & Sierra gebruikten een gegevensset, waar de verwachte afbeeldingen getekend waren met gebruik van een constante lijnbreedte en transparantie, wat betekent dat de resultaten van de training die kwaliteiten ook zouden moeten hebben. We wilden iets dat er uitzag als een beetje meer getekend met de hand, met variërende lijnbreedten of semi-transparante einden van de lijnen, dus onze gegevensset moest dat soort afbeeldingen hebben. Omdat we niet bekend waren met een gegevenssets die zou overeenkomen met onze eisen met betrekking tot de licentie en het proces van gegevens verzamelen, hebben we onze eigen gemeenschap om hulp gevraagd, hier kunt u de Krita Artists discussie erover lezen: https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401 .
De koppeling naar onze volledige gegevensset kan onderstaand gevonden worden in de sectie Gegevensset.
Modelarchitectuur
Alle hoofdlagen zijn ofwel convolutioneel of deconvolutioneel (aan het eind van het model). Na elke (de)convolutionele laag behalve de laatste is er een ReLu activatielaag en na de laatste convolutie is er een sigmoid-activatielaag.
Gebruikte Python pakketten: Pillow, Numpy, PyTorch en Openvino
Numpy is een standaard bibliotheek voor alle soorten arrays en geavanceerde array-bewerkingen en we gebruiken Pillow voor het lezen van afbeeldingen en ze converteren in numpy-arrays en terug. Voor training gebruiken we PyTorch, terwijl in de plug-in van Krita we Openvino gebruiken voor gevolgtrekking (verwerken via het netwerk).
NPU gebruiken voor gevolgtrekking

Deze tabel toont het resultaat van benchmark_app, wat een hulpmiddel is dat wordt geleverd met het Python pakket, openvino van Intel. Het test het model in isolatie op willekeurige gegevens. Zoals u kunt zien, was de NPU verschillende keren sneller dan de CPU op dezelfde machine.
Aan de andere kant, introduceren van NPU voegde een uitdaging toe: de enige modellen die kunnen draaien op NPU zijn statische modellen, wat betekent dat de invoergrootte bekend is op het moment van opslaan van het model naar een bestand. Om dat op te lossen, knipt de plug-in het werkveld in kleinere delen van een gespecificeerde grootte (die afhangt van het modelbestand), en daarna verder gaan om ze allemaal te verwerken en tenslotte stikken we de resultaten aan elkaar. Om artifacts te vermijden op de gebieden naast de stiknaad, worden alle delen opgeknipt met een beetje marge en de marge wordt er later afgeknipt.
Hoe uw eigen model te trainen
Om uw eigen model te trainen, heeft u enige technische vaardigheden nodig, paren van plaatjes (invoer en de verwachte uitvoer) en een krachtige computer. U zou ook heel wat ruimte op uw vaste schijf nodig kunnen hebben, hoewel u gewoon onnodige oudere modellen kunt verwijderen als u start en problemen heeft met gebrek aan ruimte.
Apparaatstuurprogramma's & voorbereiding
U moet Python3 installeren en de volgende pakketten: Pillow, openvino, numpy, torch. Voor kwantificering van het model zult u ook nncf nodig hebben en sklearn. Als er iets ontbreekt, zal het klagen, dus installeer die genoemde pakketten ook.
Als u op Windows bent, dan hebt u waarschijnlijk apparaatstuurprogramma's hebben voor NPU en speciale GPU. Op Linux zou u misschien NPU-apparaatstuurprogramma's moeten installeren voordat u in staat zult zijn dit: https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html te gebruiken.
Bovendien als u de iGPU wilt gebruiken voor training (wat nog steeds aanzienlijk sneller kan zijn dan op de CPU), hebt u waarschijnlijk iets nodig zoals IPEX wat aan PyTorch het gebruik van een “XPU” apparaat biedt, wat gewoon uw iGPU is. Het is niet getest of aanbevolen omdat ik persoonlijk niet in staat ben het te gebruiken omdat mijn versie van Python hoger was dan de instructie verwacht, maar de instructie is hier: https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu .
De controle op welzijn voor de installatie is als volgt:
python3 -c "import torch; import intel_extension_for_pytorch als ipex; print(f'Packages versions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Devices:'); print(f'Torch XPU device count: {torch.xpu.device_count()}'); [print(f'[Device {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
Het zou meer dan 0 apparaten moeten tonen met enige basiseigenschappen.
Als het u lukt om het XPU-apparaat te laten werken op uw machine, hebt u nog steeds het bewerken van de trainingscripts nodig zodat ze in staat zijn om het te gebruiken: https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html (meest waarschijnlijk moet u gewoon deze regel:
import intel_extension_for_pytorch toevoegen als ipex
aan het script helemaal bovenaan, net onder “import torch” en “xpu” gebruiken als de apparaatnaam bij aanroepen van het script en het zou moeten werken. Maar zoals ik zei, de scripts zijn daarvoor niet getest.
Gegevensverzameling
U hebt enige plaatjes nodig om in staat te zijn uw model te trainen. De plaatjes moeten in paren zijn, elk paar moet een schets (invoer) en een lijnkunst plaatje (verwachte uitvoer) hebben. Hoe beter de kwaliteit van de gegevensset, hoe beter het resultaat.
Voor de training is het het beste als u de gegevens verhoogt: dat betekent dat de afbeeldingen gedraaid, omhoog of omlaag geschaald en gespiegeld worden. Op dit moment voert het script voor verhogen van gegevens ook een inversie uit met de aanname dat training op geïnverteerde afbeeldingen resultaten sneller zou brengen (overwegend dat zwart nul geen signaal betekent, en we willen dat dat de achtergrond zou zijn, dus de modellen leren de lijnen, niet de achtergrond rond de lijnen).
Hoe het script voor verhogen van gegevens wordt gebruikt wordt onderstaand uitgelegd in de gedetailleerde instructie voor het onderdeel training.
Hier is de gegevensset die we hebben gebruikt (lees de licentie zorgvuldig als u het wilt gebruiken): https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
Keuze van model en andere parameters
Voor snelle resultaten, gebruik tooSmallConv; als u meer tijd en hulpbronnen hebt, is typicalDeep misschien een beter idee. Als u toegang hebt tot een krachtige GPU-machine, dan zou u original of originalSmaller willen proberen, die de originele beschrijving van het model uit het SIGGRAPH artikel door Simo-Sierra 2016 en een kleinere version ervan.
Adadelta gebruiken voor optimaliseren.
U kunt ofwel blackWhite of mse gebruiken als de loss-functie; mse is klassiek, maar blackWhite kan leiden naar snellere resultaten omdat het de relatieve fout op de volledig witte of volledig zwarte gebieden verlaagt (gebaseerd op het verwachtte uitvoerplaatje).
Oefening
Kloon de opslagruimte op https://invent.kde.org/tymond/fast-line-art (at 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.gitDaarna, prepareer de map:
- Creëer een nieuwe map voor de oefening
- In de map, voet uit:
python3 [opslagruimtemap]/spawnExperiment.py --path [pad naar nieuwe map, ofwel relatief of absoluut] --note "[uw persoonlijke notitie over het experiment]"
Gegevens prepareren
- Als u een bestande verhoogde gegevensset hebt, zet ze allemaal in data/training/ en data/verify/, met bedenken dat gepaarde afbeeldingen in submappen ink/ en sketch/ exact dezelfde namen moeten hebben (bijvoorbeeld als u sketch.png en ink.png als gegevens hebt, moet u er een in sketch/ als picture.png zetten en een andere in ink/ als picture.png om gepaard te zijn).
- Als u geen bestaande verhoogde gegevensset hebt:
- Zet al uw raw-gegevens in data/raw/, bedenk dat gepaarde afbeeldingen dezelfde namen zouden moeten hebben de exact zelfde namen met het toegevoegde voorvoegsel ofwel ink_ of sketch_ (bijvoorbeeld als u picture_1.png hebt die de schetsafbeelding is en picture_2.png de inkt afbeelding, u moet ze respectievelijk de naam geven sketch_picture.png en ink_picture.png.)
- Voer het scrip voor gegevens voorbereiden uit:
python3 [repository folder]/dataPreparer.py -t taskfile.yml
Die zal de gegevens in de raw-map verhogen om de training met meer succes te voltooien.
Bewerk het bestand taakfile.yml naar wat u wilt. De belangrijkste delen die u wilt wijzigen zijn:
- modeltype - codenaam voor het modeltype, gebruik tinyTinier, tooSmallConv, typicalDeep of tinyNarrowerShallow
- optimizer - type optimizer, gebruik adadelta of sgd
- learning rate - leersnelheid voor sgd indien in gebruik
- loss function - codenaam voor verliesfunctie, gebruik mse voor gemiddelde vierkantsfout of blackWhite voor een eigen verliesfunctie gebaseerd op mse, maar een beetje kleiner voor pixels waar de pixelwaarde van het doel dichtbij is 0,5 is
Voer de trainingscode uit:
python3 [opslagruimtemap]/train.py -t taskfile.yml -d "cpu"Op Linux, als u het wilt uitvoeren in een achtergrond, voeg “&” toe aan het eind. Als het in een voorgrond wordt uitgevoerd, kunt u de training pauzeren door eenvoudig Ctrl+C in te drukken, en als het in een achtergrond draait, zoek een proces-id (ofwel met de opdracht “jobs -l” of de opdracht “ps aux | grep train.py”, het eerste getal zou het proces-id moeten zijn) en kill het met de opdracht “kill [proces-id]”. Uw resultaten zullen nog steeds in de map zijn en u zult in staat zijn om de training te hervatten met dezelfde opdracht.
Converteer het model naar een openvino model:
python3 [opslagruimtemap]/modelConverter.py -s [grootte van de invoer, aanbevolen 256] -t [invoermodelnaam, uit pytorch] -o [openvino-modelnaam, moet eindigen met .xml]Plaats beiden de .xml en .bin modelbestanden in uw hulpbronmap van Krita (in de submap pykrita/fast_sketch_cleanup) naast andere modellen om ze in de plug-in te gebruiken.