Approfondimento sull'estensione Fast Sketch Cleanup per Krita
Estensione Fast Sketch Cleanup
Introduzione
Abbiamo iniziato questo progetto con l'intenzione di fornire agli utenti uno strumento utile per l'inchiostrazione di schizzi/bozzetti. Si è basato su un articolo di ricerca di Simo e Sierra, pubblicato nel 2016, e per funzionare utilizza le reti neurali (ora chiamate più comunemente IA, intelligenza artificiale). Lo strumento è stato sviluppato in collaborazione con Intel ed è considerato sperimentale, ma puoi già utilizzarlo e vederne i risultati.
Nella sezione sottostante sono riportati alcuni esempi di vita reale di casi d'uso e i risultati dall'estensione. I risultati variano, ma l'estensione può essere utilizzata per estrarre dei leggeri schizzi di matita dalle fotografie, per ripulire le linee e inchiostrare un fumetto.
Per ciò che riguarda lo strumento, il modello utilizzato è stato addestrato da noi. Tutti i dati nel gruppo di dati ci è stato donato da persone che hanno inviato le loro immagini e hanno acconsentito al loro utilizzo in questo specifico caso d'uso. Non abbiamo utilizzato altri dati. Inoltre, quando utilizzi l'estenzione, essa elabora localmente i dati e non richiede alcun collegamento a Internet, non si collega a un server e non è necessaria l'impostazione di alcun account. Attualmente funziona soltanto su Windows e Linux, ma stiamo lavorando per farla funzionare anche su macOS.
Casi d'uso
Calcola la media delle linee in una linea e crea linee nere forti, ma il risultato finale può essere sfocato o irregolare. In molti casi funziona ancora meglio che usare semplicemente un filtro Livelli (per esempio, nell'estrazione della matita schizzo). Potrebbe essere una buona idea utilizzare il filtro Livelli dopo aver usato l'estensione per ridurre la sfocatura. Dato che l'estensione lavora meglio con tela bianca e linee grigio-nere, nel caso di schizzi di matita fotografati o linee molto leggere, sarebbe meglio utilizzare i Livelli anche prima di usare l'estensione.
Estrazione di uno schizzo di matita fotografato
Questo è il risultato del metodo standard per estrarre le linee con utilizzo del filtro Livelli su uno schizzo (il risultato è che una parte dell'immagine riceve l'ombra):

sketch_girl_original_procedure_comparison_small1843×1209 165 KB
Lo schizzo è stato disegnato da Tiar (collegamento al profilo K.A.)
Questo è il metodo tramite uso dell'estensione con lo SketchyModel (Livelli → estensione → Livelli):

sketch_girl_new_procedure_comparison_small1843×2419 267 KB
Confronto (delle linee nere):

sketch_girl_procedures_comparison_small1920×1260 215 KB
Un'altra possibile soluzione sarebbe fermarsi all'estensione senza forzare le linee nere tramite l'uso dei Livelli, che restituirebbe un aspetto più carino, simile alla matita di tipo giallo, sempre mantenendo bianca la parte inferiore della pagina:

sketch_girl_after_plugin_small1536×2016 161 KB
Inchiostrazione in stile fumetto
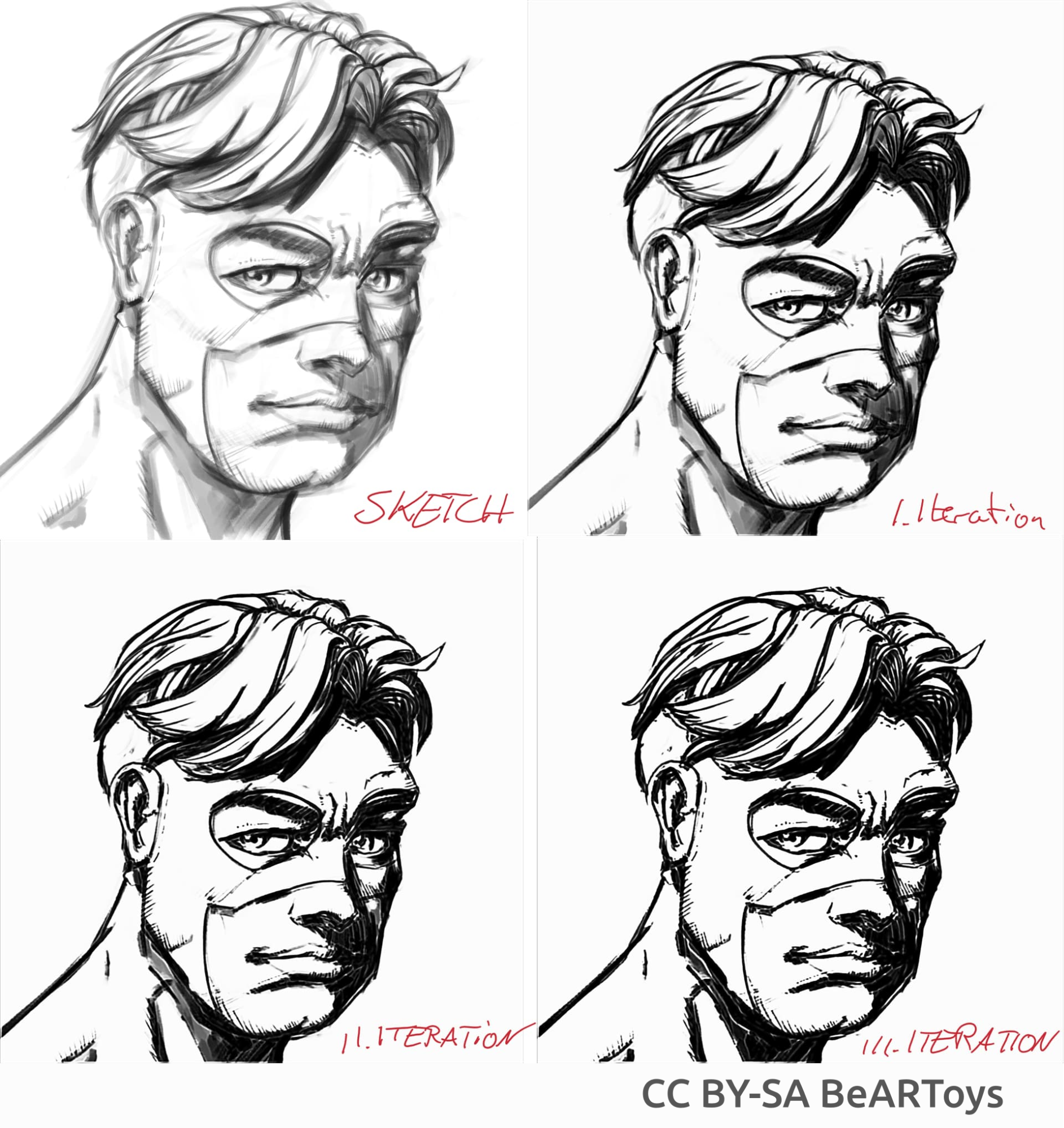
Picture of a man made di BeARToys

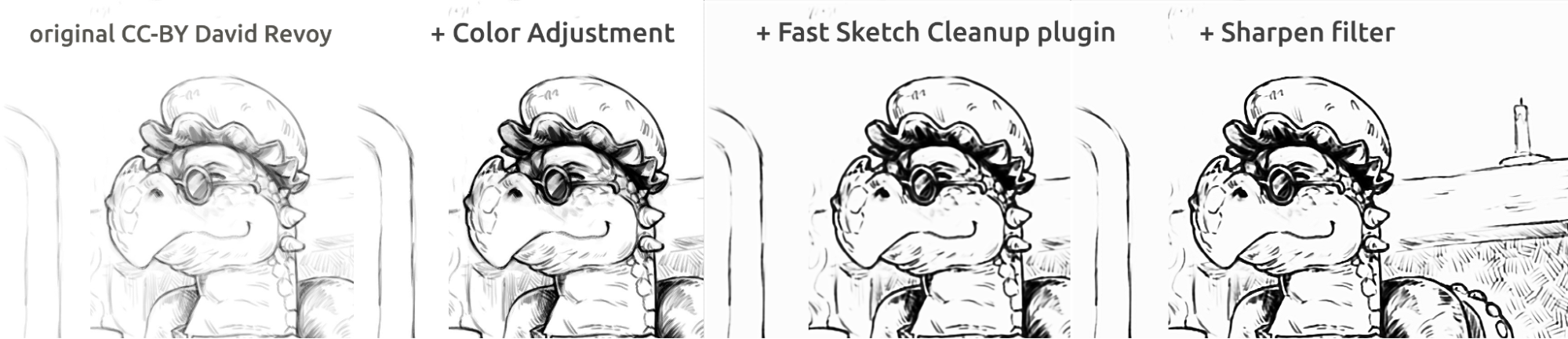
Nelle figure riportate sopra puoi osservare l'inchiostrazione in stile fumetto. Il risultato, un po' sfocato rispetto all'originale, può essere migliorato ulteriormente utilizzando un filtro Nitidezza. Il drago è stato disegnato da David Revoy (CC-BY 4.0).
Ripulitura delle linee
Esempi di schizzi fatti da me e il risultato dell'estensione, che mostrano i punti di forza e debolezza dell'estensione. Tutte le immagini sotto riportate sono state create utilizzando lo SketchyModel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flower_001_detail681×456 22.1 KB
{kind=link}

portrait_man_portrait_2_comparison_2_small1305×505 139 KB
{kind=link}

portrait_man_portrait_2_detail646×1023 26.6 KB
{kind=link}
Tutte le immagini disegnate sopra sono di Tiar (collegamento al profilo K.A.)
Nelle figure sotto riportate, puoi osservare le squame del pesce e notare come il modello distingue le linee più tenui e migliora le linee più accentuate, rendendo le squame più pronunciate. In teoria potresti fare la stessa operazione con il filtro Livelli, ma in pratica il risultato sarebbe peggiore perché il modello prende in considerazione l'intensità locale della linea.
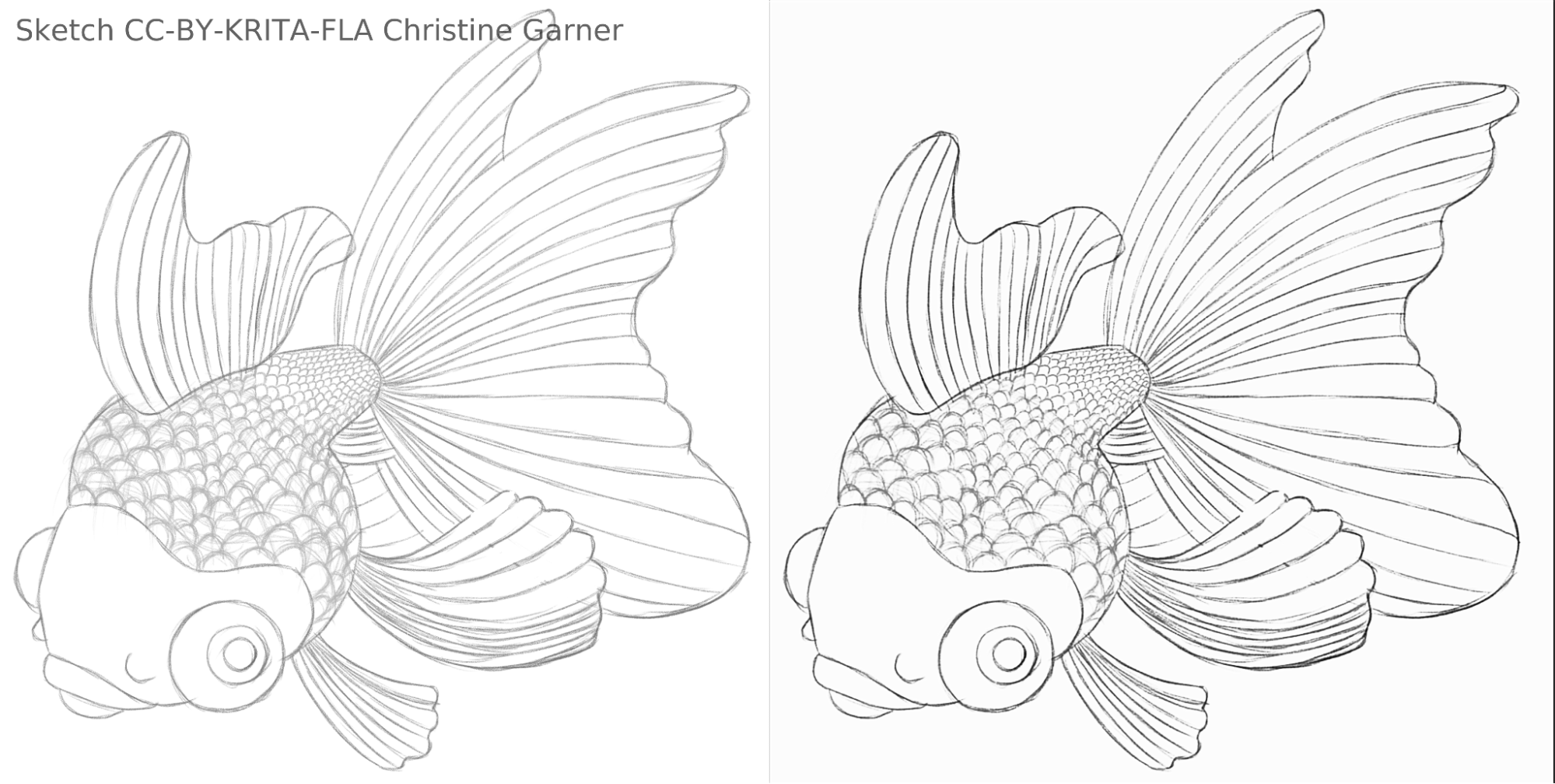
fish_square_sketchy_comparison_small1920×968 156 KB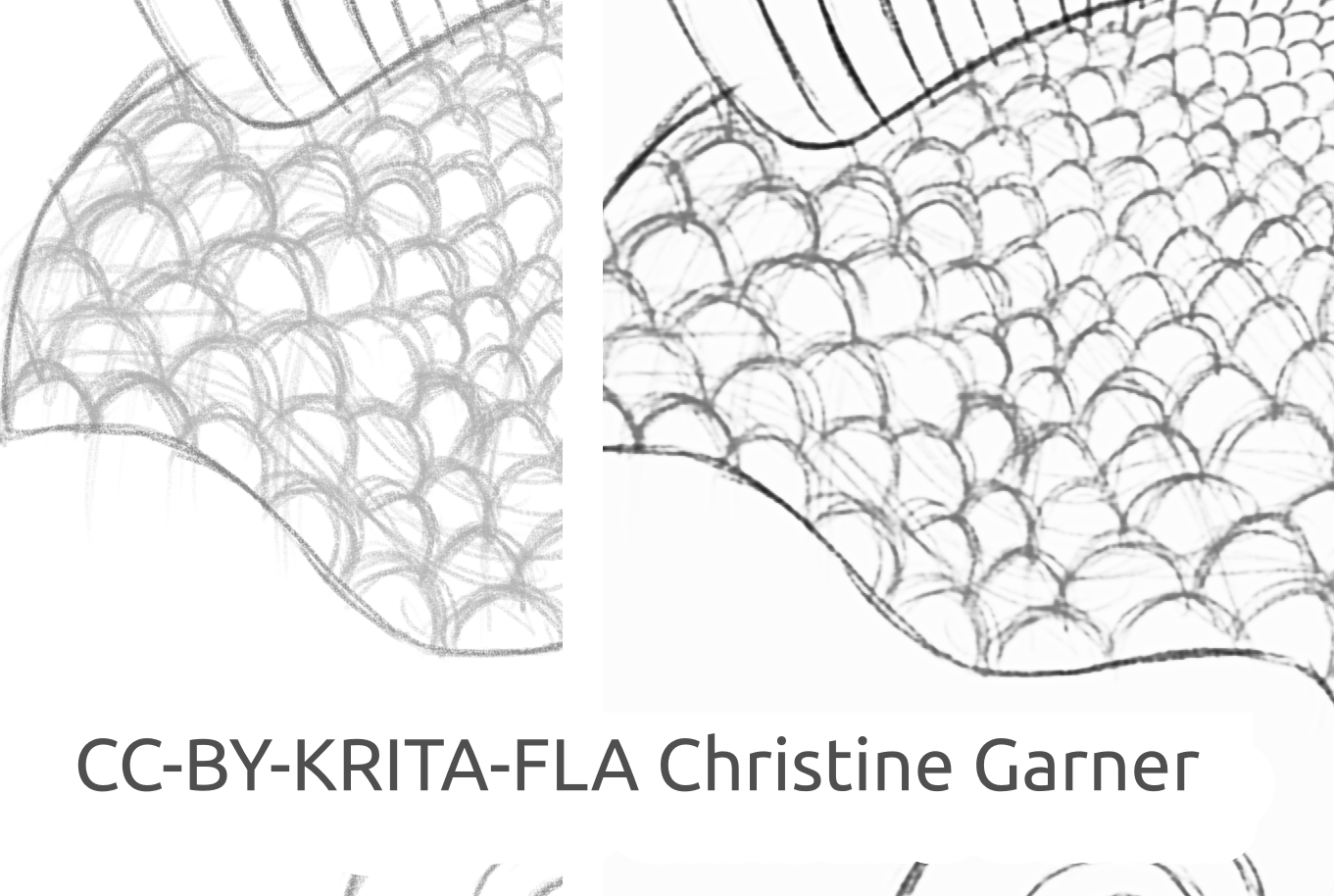
{kind=link}
Disegno del pesce fatto da Christine Garner (collegamento al portfolio)
Come utilizzare l'estensione in Krita
Per utilizzare l'estensione Fast Sketch Cleanup in Krita, procedi nel modo seguente:
- Preparazione di Krita:
- In Windows:
- O in un unico pacchetto: scarica Krita 5.3.0-prealpha già comprensivo dell'estensione Fast Sketch Cleanup: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.zip
- O separatamente:
- Scarica la versione portatile di Krita 5.2.6 (o una versione simile - dovrebbe funzionare)
- Scarica separatamente l'estensione Fast Sketch Cleanup da qui: https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- Decomprimi il file nella cartella di krita-5.2.6/ (mantenendo la struttura della cartella).
- Quindi vai a Impostazioni → Configura Krita → Gestore estensioni Python, abilita l'estensione "Fast Sketch Cleanup" e riavvia Krita.
- In Linux:
- Scarica la appimage: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
- In Windows:
- (Facoltativo) Installa i driver NPU, se nel tuo dispositivo hai NPU (necessario soltanto in Linux, in pratica, se hai una CPU Intel molto nuova): configurazioni Intel® NPU con OpenVINO™ — documentazione OpenVINO™ (nota: puoi ancora eseguire l'estensione su CPU o GPU, non richiede NPU)
- Esegui l'estensione:
- Apri o crea una tela bianca con tratteggi grigio-bianchi (nota che l'estensione prenderà la proiezione attuale della tela, non l'attuale livello).
- Vai a Strumenti → Fast Sketch Cleanup
- Seleziona il modello. Saranno selezionate automaticamente le opzioni avanzate.
- Attendi che termini l'elaborazione (la finestra di dialogo si chiuderà quindi automaticamente).
- Nota che è stato creato un nuovo livello con il risultato.
Consigli per l'elaborazione
Attualmente è meglio usare soltanto SketchyModel.xml, nella maggior parte dei casi funziona decisamente meglio di SmoothModel.xml.
Devi accertarti che lo sfondo sia sufficientemente chiaro, e che le linee che vuoi mantenere nel risultato siano relativamente scure (qualcosa tra il grigio scuro e il nero; il grigio chiaro potrebbe generare molte linee mancanti). Potrebbe essere una buona idea usare prima un filtro tipo Livelli.
Dopo l'elaborazione, a seconda del risultato ottenuto, potresti voler migliorare lo schizzo o col filtro Livelli o col filtro Nitidezza.
Tecnologia e scienza utilizzate nell'estensione
Requisiti particolari
Il primo e peculiare requisito era che l'estensione doveva funzionare su tele di qualsiasi dimensione. Ciò implicava che la rete non poteva avere livelli lineari densi o completamente o densamente connessi, che sono molto comuni nella maggior parte delle reti neurali di elaborazione delle immagini (che richiedono input di una dimensione specifica e producono risultati diversi per lo stesso pixel a seconda della sua posizione), ma solo convoluzioni o livelli di pooling o simili che producevano gli stessi risultati per ogni pixel della tela, indipendentemente dalla posizione. Fortunatamente il lavoro di Simo e Sierra pubblicato nel 2016 descriveva una rete proprio come quella.
Un'altra sfida era che non potevano davvero usare il modello che avevano creato, dato che era incompatibile con la licenza di Krita, e non potevamo usare neanche usare il tipo di modello esatto che avevano descritto, perché uno di quei file modello sarebbe stato grande quasi quanto Krita, e l'addestramento avrebbe richiesto un tempo lunghissimo. Avevamo bisogno di qualcosa che funzionasse altrettanto bene, se non meglio, ma abbastanza piccolo da poter essere aggiunto a Krita senza rendere il programma due volte più grande (in teoria potevamo procedere come avevano fatto altre aziende e far girare l'elaborazione in un server di qualche tipo, ma non era quello che volevamo. E anche se avesse risolto alcuni dei nostri problemi, ci avrebbe posto dinanzi a una delle sue sfide più grandi. Inoltre, volevamo che i nostri utenti potessero utilizzarlo in locale, senza dover dipendere dai nostri server e da Internet). Per di più, il modello doveva essere ragionevolmente veloce e parco in termini di consumi RAM/VRAM.
Tra l'altro, non avevamo alcun gruppo di dati da usare. Simo e Sierra avevano utilizzato un gruppo di dati in cui le immagini attese erano tutte disegnate usando linee con trasparenza e larghezza costanti, il che significava che i risultati dell'addestramento avevano anch'essi quella qualità. Noi volevamo qualcosa che sembrasse più fatto a mano, con variazioni di spessore e con terminali semi trasparenti, dunque il nostro gruppo di dati doveva contenere quel genere di immagini. Poiché non eravamo, non siamo, a conoscenza di alcun gruppo di dati che soddisfi i nostri requisiti in merito alla licenza e al processo di raccolta, chiedemmo aiuto alla nostra comunità, e qui puoi leggere la relativa conversazione in Krita Artists: https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401.
Il collegamento al nostro gruppo di dati si trova più avanti, nella sezione Gruppo di dati.
Architettura dei modelli
Tutti i livelli principali sono o convolutivi o deconvolutivi (alla fine del modello). Dopo ogni livello (de)convolutivo, ad eccezione dell'ultimo, c'è un livello di attivazione ReLu, e dopo l'ultima convoluzione è presente un livello di attivazione sigmoidea.
Pacchetti Python utilizzati: Pillow, Numpy, PyTorch e OpenVINO
Numpy è una libreria standard per tutti i tipi di matrice e operazioni avanzate sulle matrici. Abbiamo usato Pillow per leggere le immagini e convertirle in matrice e poi riconvertirle. Per l'addestramento abbiamo usato PyTorch, mentre nell'estensione Krita abbiamo utilizzato OpenVINO per l'inferenza (elaborazione attraverso la rete).
Uso della NPU per l'inferenza

Questa tabella mostra il risultato di benchmark_app, uno strumento fornito con il pacchetto Python di Intel, OpenVINO. Testa il modello in modo isolato su dati casuali. Come puoi vedere, la NPU è diverse volte più veloce della CPU sulla stessa macchina.
D'altro lato, l'introduzione della NPU ha aggiunto una sfida: gli unici modelli in grado di girare sulla NPU sono modelli statici, il che significa che la dimensione del file di ingresso è conosciuta al momento del salvataggio del modello nel file. Per risolvere questo problema, l'estensione prima scompone la tela in parti più piccole di dimensione specificata (che dipende dal file del modello), quindi procede a elaborare tutte le parti e infine ricompone il risultato. Per evitare artefatti sulle aree adiacenti all'incollaggio, tutte le parti vengono tagliate con un po' di margine e il margine viene in seguito eliminato.
Addestramento del tuo modello
Per addestrare il tuo modello personalizzato, avrai bisogno di alcune conoscenze tecniche, di coppie di immagini (ingresso e risultato atteso) e un computer potente. Ti potrebbe servire anche un bel po' di spazio sul disco, anche se puoi rimuovere i modelli più vecchi non necessari, nel caso ti serva più spazio.
Driver e preparazione
Dovrai installare Python3 e i pacchetti seguenti: Pillow, openvino, numpy, torch. Per la quantizzazione del modello avrai bisogno anche di nncf e sklearn. Se ho dimenticato qualcosa, ti verrà richiesto, dunque installa solo quei pacchetti che ho detto.
Se sei in Windows, hai probabilmente i driver per la NPU e la GPU dedicata. In Linux devi installare i NPU prima di poter usare l'estensione: https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html .
Inoltre, se vuoi utilizzare una iGPU per l'addestramento, che potrebbe essere molto più veloce che sulla CPU), dovrai probabilmente usare qualcosa tipo IPEX, che permette a PyTorch di usare un dispositivo “XPU”, che non è altro che la tua iGPU. Non è testato o consigliato, pertanto non ho potuto utilizzarla personalmente perché la mia versione di Python rispetto a quella richiesta dalle istruzioni, che si trovano qui: https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu .
Il sanity test per l'installazione è il seguente:
python3 -c "import torch; import intel_extension_for_pytorch as ipex; print(f'Packages versions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Devices:'); print(f'Torch XPU device count: {torch.xpu.device_count()}'); [print(f'[Device {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
Dovrebbe mostrare più di 0 dispositivi con proprietà di base.
Se cerchi di far funzionare il tuo dispositivo XPU sulla tua macchina, dovrai modificare ancora i tuoi script di addestramento in modo che lo possano utilizzare: https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html (molto probabilmente dovrai aggiungere questa riga:
import intel_extension_for_pytorch as ipex
in cima allo script, subito sotto “import torch”, e usare “xpu” come nome del dispositivo quando invochi lo script, e dovrebbe funzionare. Attenzione però, perché gli script non sono stati testati per quello.
Gruppo di dati
Per addestrare il modello avrai bisogno di alcune immagini. Queste devono essere in coppia, ogni coppia deve contenere uno schizzo (ingresso) e un'immagine lineart (risultato atteso). Migliore è la qualità del gruppo di dati, migliore sarà il risultato.
Prima di iniziare l'addestramento, è meglio accrescere i dati, ossia le immagini vanno ruotate, ingrandite o rimpicciolite, e ribaltate. Al momento, lo script di accrescimento dati esegue anche un'inversione, presumendo che l'addestramento sulle immagini invertite produca più velocemente i risultati (considerando che nero significa zero significa nessun segnale, e preferiremmo che fosse lo sfondo, così i modelli apprendono le linee, non lo sfondo attorno alle linee).
La spiegazione sull'utilizzo dello script di accrescimento dati è riportata in modo dettagliato nella parte relativa all'addestramento.
Qui c'è il gruppo di dati che abbiamo utilizzato (leggi attentamente la licenza se vuoi utilizzarlo): https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
Scelta del modello e altri parametri
Per risultati rapidi, usa tooSmallConv; se disponi di più tempo e risorse, altra soluzione sarebbe typicalDeep. Se hai accesso a una macchina con GPU potente, potresti provare l'originale oppure originalSmaller, che rappresenta la descrizione originale del modello dall'articolo SIGGRAPH di Simo-Sierra 2016, e una sua versione più piccola.
Usa adadelta per l'ottimizzazione.
Puoi usare blackWhite o mse per la funzione "loss"; mse è classico, ma blackWhite produce risultati più veloci, dato che riduce l'errore relativo sulle aree completamente bianche o completamente nere (basato sull'immagine del risultato atteso).
Addestramento
Clona il deposito in https://invent.kde.org/tymond/fast-line-art (at 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.gitPoi prepara la cartella:
- Crea una nuova cartella per l'addestramento.
- Nella cartella, esegui:
python3 [cartella del deposito]/spawnExperiment.py --path [percorso alla nuova cartella, relativo o assoluto] --note "[le tue note personali sull'esperimento]"
Prepara i dati:
- Se sei in possesso di un gruppo di dati accresciuto, metti tutto in data/training/ e data/verify/, tenendo presente che le immagini accoppiate nelle sottocartelle ink/ e sketch/ subfolders devono avere lo stesso nome (per es., se come dati hai un'immagine che si chiamo sketch.png e l'altra che si chiamo ink.png, devi metterne una in sketch/ come picture.png e un'altra in ink/ sempre come picture.png in modo da essere accoppiate).
- Se non sei in possesso di un gruppo di dati accresciuto:
- Metti tutti i tuoi dati grezzi in data/raw/, tenendo presente che le immagini accoppiate devono avere lo stesso nome col prefisso aggiunto ink_ o sketch_ (per es., se hai picture_1.png come immagine sketch e picture_2.png come immagine ink, devi rinominarle rispettivamente sketch_picture.png e ink_picture.png.)
- Esegui lo script "data preparer":
python3 [cartella del deposito]/dataPreparer.py -t taskfile.yml
Questo comando accrescerà i dati nella cartella raw affinché l'addestramento riesca meglio.
Modifica il file taskfile.yml a tuo piacimento. Le parti più importanti che potresti cambiare sono:
- model type - nome del codice per il tipo di modello, usa tinyTinier, tooSmallConv, typicalDeep o tinyNarrowerShallow
- optimizer - tipo di ottimizzazione, usa adadelta o sgd
- learning rate - velocità di apprendimento per sgd, se in uso
- loss function - nome del codice per la funzione loss, usa mse per l'errore quadratico medio o blackWhite per una funzione loss personalizzata basata su mse, ma un po' più piccola per i pixel in cui il valore dei pixel dell'immagine di destinazione è vicino a 0,5
Esegui il codice di addestramento:
python3 [cartella del deposito]/train.py -t taskfile.yml -d "cpu"In Linux, se vuoi eseguirlo in background, aggiungi “&” alla fine. Se lo esegui in primo piano, puoi mettere l'addestramento in pausa premendo Ctrl+C, mentre se lo esegui in background, trova un ID del processo (tramite il comando “jobs -l” o il comando “ps aux | grep train.py”, il primo numero dovrebbe essere l'ID del processo) e terminalo col comando “kill [ID del processo]”. I risultati saranno ancora nella cartella, e potrai riprendere l'addestramento usando lo stesso comando.
Converti il modello in un modello OpenVINO:
python3 [cartella di destinazione]/modelConverter.py -s [dimensione di ingresso, raccomandato 256] -t [nome modello in ingresso, da pytorch] -o [nome modello openvino, deve terminare per .xml]Metti i file del modello .xml e .bin nella cartella delle risorse di Krita (all'interno della sottocartella pykrita/fast_sketch_cleanup) accanto agli altri modelli da usare nell'estensione.