Plongeons dans le module externe « Fast Sketch Cleanup » pour Krita
Module externe de nettoyage rapide de croquis
Introduction
Nous avons lancé ce projet dans le but de fournir aux utilisateurs un outil utile pour l'encrage des croquis. Il repose sur un article de recherche de Simo et Sierra publié en 2016. Il utilise des réseaux de neurones (Maintenant communément appelés simplement IA) pour fonctionner. L'outil a été développé en partenariat avec Intel. Il est toujours considéré comme expérimental, mais vous pouvez déjà l'utiliser et voir les résultats.
Dans la section ci-dessous, il y a quelques exemples réels de cas d'utilisation et les résultats du module externe. Les résultats varient, mais le module externe peut être utilisé pour extraire des croquis fait avec un crayon pâle à partir de photos, pour nettoyer des lignes et pour encrer des bandes dessinées.
En ce qui concerne le modèle utilisé dans l'outil, nous l'avons entraîné nous-mêmes. Toutes les données dans le jeu de données proviennent de personnes qui nous ont envoyé leurs photos et ont convenu de ce cas d'utilisation spécifique. Nous n'avons pas utilisé d'autres données. De plus, lorsque vous utilisez le module externe, il fonctionne localement sur votre machine, il ne nécessite aucune connexion Internet, ne se connecte à aucun serveur et aucun compte n'est requis. Actuellement, il fonctionne uniquement sous Windows et Linux. Mais, nous travaillons aussi sur sa mise à disposition sous MacOS.
Cas d'utilisation
Il fait la moyenne des lignes en une seule ligne et crée de lignes noires marquées. Mais le résultat final peut être flou ou inégal. Dans de nombreux cas, il fonctionne toujours mieux que lors de l'utilisation d'un filtre « Niveaux » (Par exemple pour l'extraction d'un croquis au crayon). Cela serait peut-être plus judicieux d'utiliser le filtre « Niveaux » après avoir utilisé le module externe pour réduire le flou. Puisque le module externe fonctionne mieux avec un canevas blanc et des lignes grise ou noire, en cas de croquis au crayon photographié ou des lignes légères de croquis. Cela pourrait être aussi une bonne idée d'utiliser « Niveaux » avant d'utiliser le module externe.
Extraction en cours d'un croquis au crayon photographié
C'est le résultat de la procédure standard consistant à utiliser le filtre « Niveaux » sur un croquis pour extraire les lignes (Ce qui fait qu'une partie de l'image est ombrée) :

sketch_girl_original_procedure_comparison_small1843×1209 165 KB
Le croquis a été dessiné par Tiar (Lien vers le profil KA).
C'est la procédure utilisant le module externe avec SketchyModel (Niveaux /Module externe / Niveaux) :

sketch_girl_new_procedure_comparison_small1843×2419 267 KB
Comparaison (Pour les lignes noires) :

sketch_girl_procedures_comparison_small1920×1260 215 KB
Un autre résultat possible est de simplement s'arrêter au module externe sans forcer les lignes noires à l'aide de « Niveaux ». Cela conduit à une apparence plus agréable et plus comme un crayonnage, tout en gardant la partie inférieure de la page toujours vierge :

sketch_girl_after_plugin_small1536×2016 161 KB
Encrage de type bande dessinée
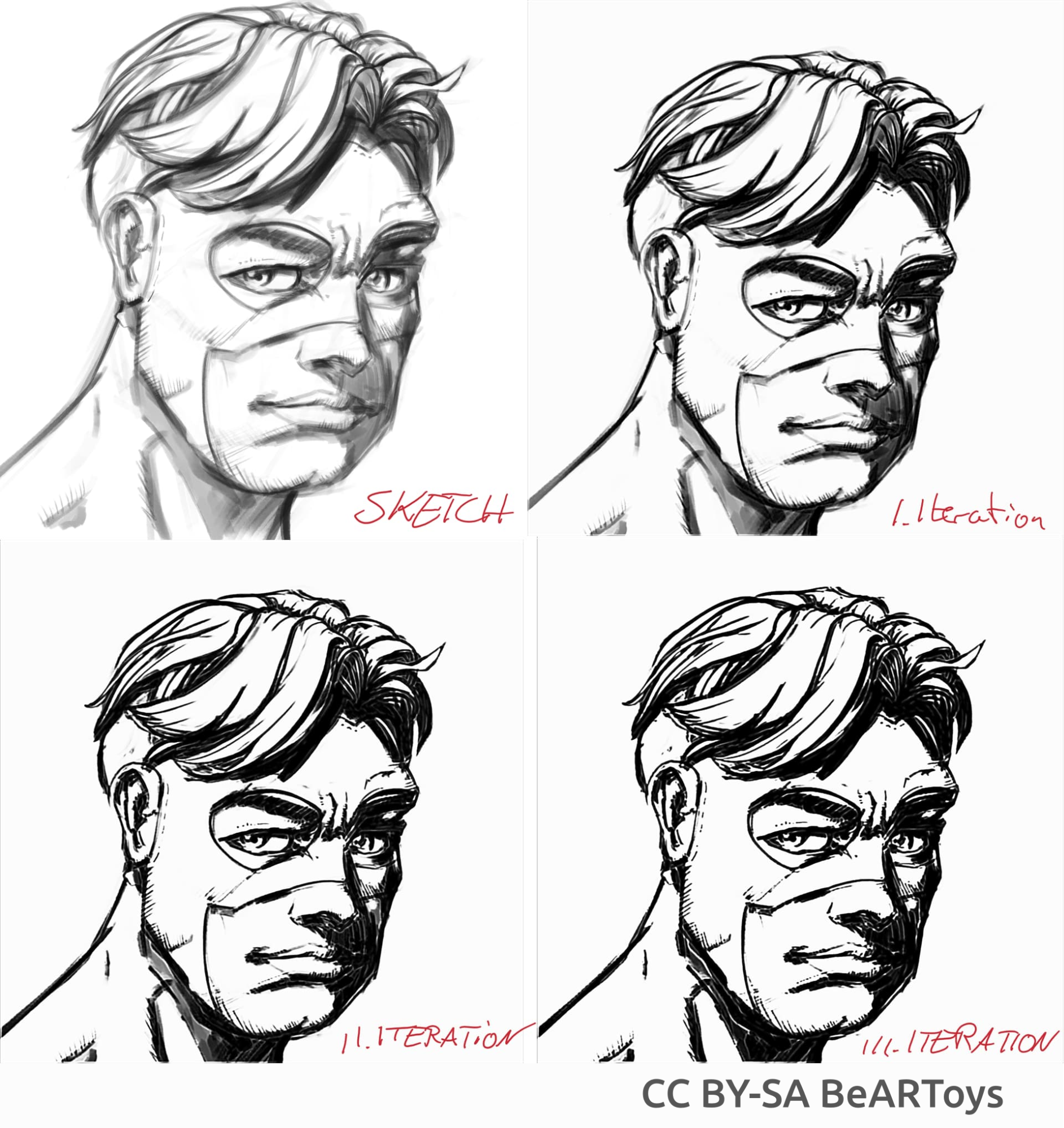
Photo de l'homme réalisée par BeARToys

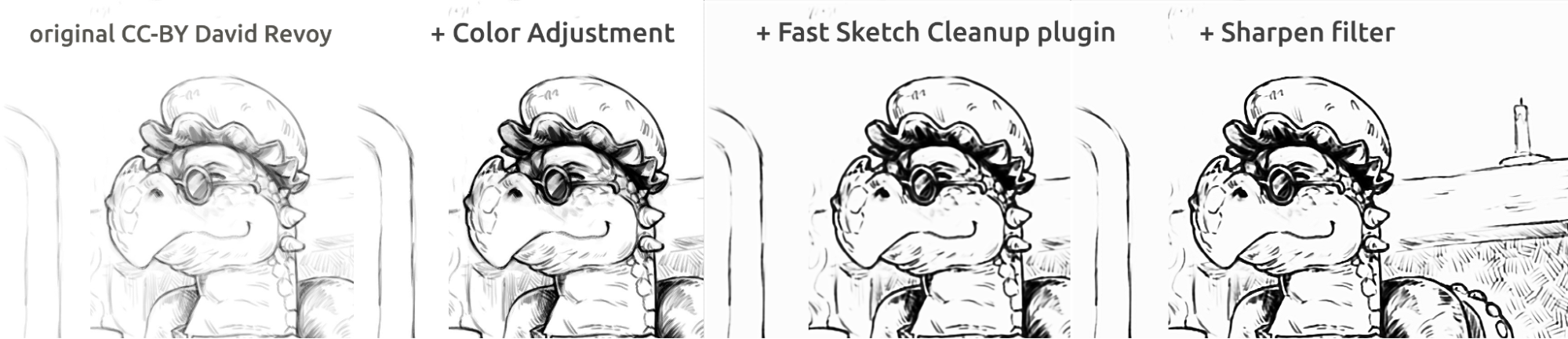
Vous trouverez ici, dans les images ci-dessus, l'encrage de style bande dessinée. Le résultat, qui est un peu flou par rapport à l'original, peut être encore amélioré en utilisant un filtre « Accentuer ». Le dragon a été esquissé par David Revoy(CC-BY 4.0).
Nettoyage des lignes
Des exemples de croquis que j'ai réalisés et le résultat du module externe, montrant les points forts et les points faibles du module externe. Toutes les images ci-dessous ont été réalisées à l'aide de SketchyModel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flower_001_detail681×456 22.1 KB
{kind=link}

portrait_man_portrait_2_comparison_2_small1305×505 139 KB
{kind=link}

portrait_man_portrait_2_detail646×1023 26.6 KB
{kind=link}
Toutes les photos ci-dessus sont peintes par Tiar (Lien vers le profil KA)
Sur les images ci-dessous, sur les écailles du poisson, vous pouvez voir comment le modèle distingue les lignes plus claires et améliore les lignes plus foncées, rendant les écailles plus prononcées. En théorie, vous pourriez le faire en utilisant le filtre « Niveaux » mais, dans la pratique, les résultats seraient pires, car le modèle prend en compte la force locale de la ligne.
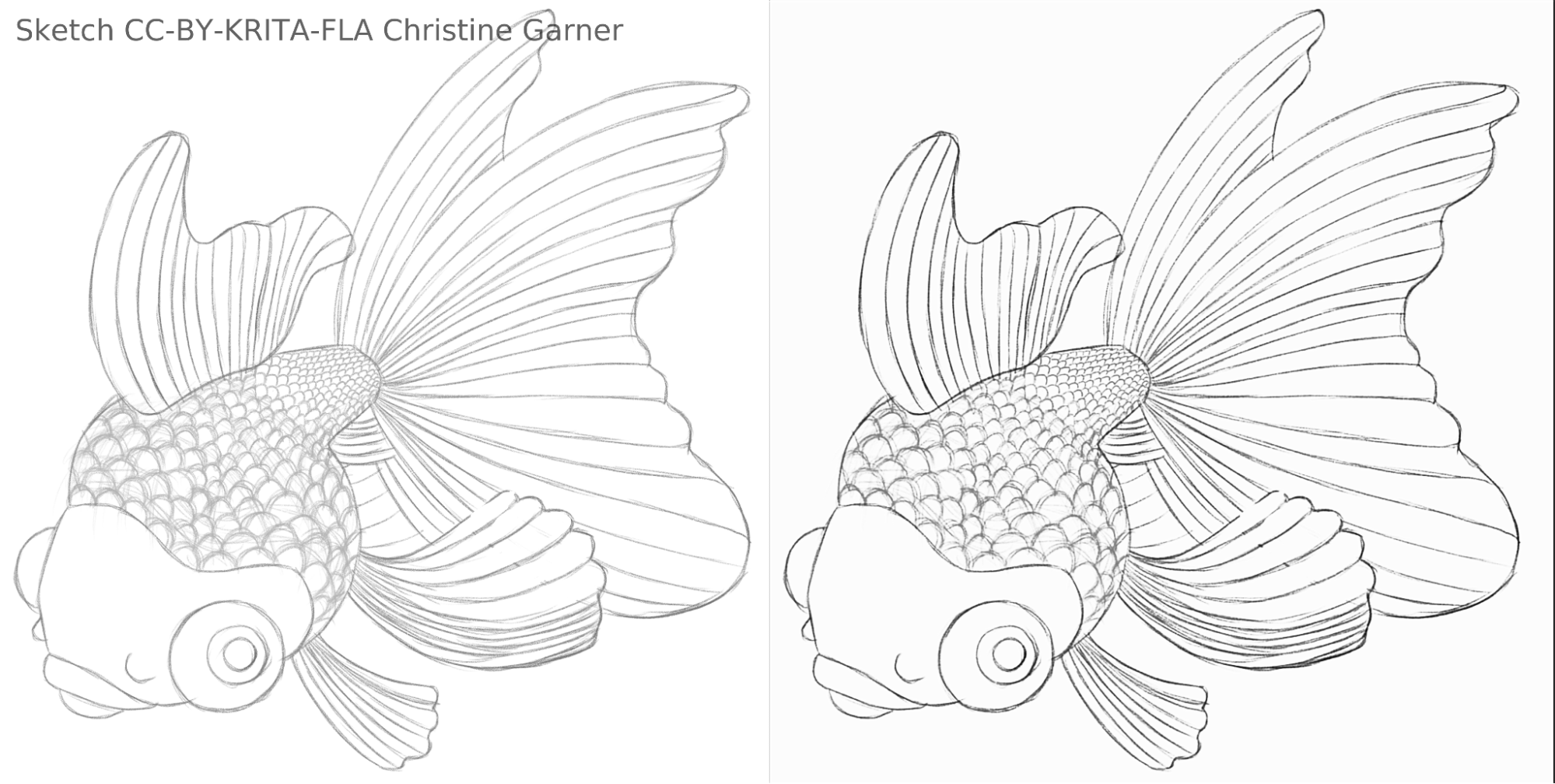
fish_square_sketchy_comparison_small1920×968 156 KB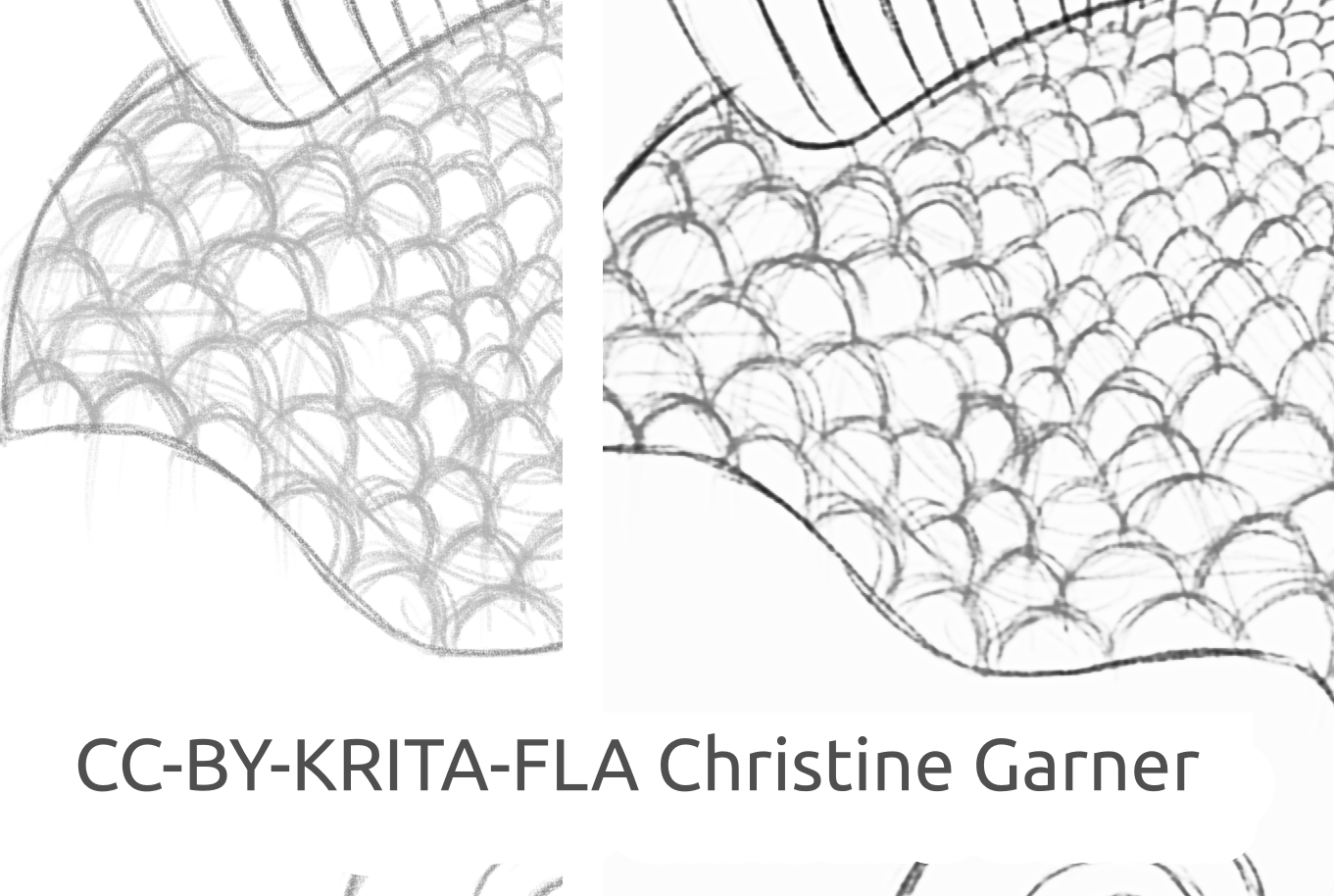
{kind=link}
Photo du poisson faite par Christine Garner (Lien vers le portfolio)
Comment l'utiliser dans Krita
Pour utiliser le module externe « Fast Sketch Cleanup » dans Krita, veuillez procéder comme suit :
- Préparer Krita :
- Sous Windows :
- Soit dans un paquet : télécharger Krita 5.3.0-prealpha avec le module externe « Fast Sketch Cleanup » déjà intégré : https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.zip
- Ou séparément :
- Télécharger la version portable de Krita 5.2.6 (Ou une version similaire\ - Devrait toujours fonctionner)
- Téléchargez le module externe « Fast Sketch Cleanup » séparément ici : https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- Décompressez le fichier dans le dossier « krita-5.2.6 / » (En conservant la structure du dossier).
- Ensuite, veuillez aller dans Paramètres / Configurer Krita / Gestionnaire de modules externes Python, activer le module « Fast Sketch Cleanup » et redémarrer Krita.
- Sous Linux :
- Télécharger le fichier « AppImage » : https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
- Sous Windows :
- (Facultatif) Installez les pilotes pour le processeur « NPU » si vous avez un tel processeur sur votre périphérique (Pratiquement nécessaire uniquement sous Linux, si vous avez un tout nouveau processeur Intel) : Configurations pour Intel® NPU avec documentation OpenVINO™ — OpenVINO™ (Remarque : vous pouvez toujours lancer le module externe sur le processeur ou sur un processeur « GPU », il ne nécessite aucun processeur « NPU »)
- Exécutez le module externe :
- Ouvrez ou créez un canevas blanc avec des traits gris-blanc (Veuillez noter que le module externe prendra la projection courante du canevas et non le calque courant).
- Aller dans les outils / Nettoyage rapide des croquis
- Veuillez sélectionner le modèle. Les options avancées seront automatiquement sélectionnées pour vous.
- Veuillez attendre qu'il ait terminé le traitement (La boite de dialogue se fermera alors automatiquement).
- Veuillez regarder qu'il a créé un nouveau calque avec le résultat.
Conseils pour le traitement
Actuellement, il est préférable d'utiliser simplement le fichier « SketchyModel.xml », dans la plupart des cas. Il fonctionne nettement mieux que le fichier « SmoothModel.xml ».
Vous devez vous assurer que l'arrière-plan est assez lumineux et que les lignes que vous souhaitez conserver dans le résultat sont relativement sombres (Gris foncé ou noir. Le gris clair peut entraîner de nombreuses lignes manquées). Cela pourrait être une bonne idée d'utiliser un filtre comme « Niveaux » au préalable.
Après le traitement, vous souhaiterez peut-être améliorer les résultats avec, soit le filtre « Niveaux », soir le filtre « Accentuer », en fonction de vos résultats.
La technologie et la science derrière lui
Exigences uniques
La première exigence unique était qu'il devait travailler sur des canevas de toutes tailles. Cela signifiait que le réseau ne pouvait pas avoir de calques linéaires connectés de façon dense /entièrement ou densément, très courantes dans la plupart des traitements d'image avec des réseaux de neurones (Qui nécessitent une entrée de taille spécifique et produiront différents résultats pour le même pixel selon son emplacement), avec seulement les convolutions ou la mise en commun ou des calques similaires qui produisaient le même résultats pour chaque pixel du canevas, indépendamment de l'emplacement. Heureusement, l'article de Simo et Sierra publié en 2016 décrivait un réseau de ce genre.
Un autre défi était que nous ne pouvions pas vraiment utiliser le modèle qu'ils ont créé, car il n'était pas compatible avec la licence de Krita. Nous ne pouvions même pas vraiment utiliser le type exact de modèle qu'ils ont décrit, car l'un de ces fichiers de modèle aurait été presque aussi volumineux que Krita et l'entraînement aurait été particulièrement long. Nous avions besoin de quelque chose qui fonctionnerait aussi bien, sinon mieux, mais suffisamment petit pour être ajouté à Krita sans devoir doubler sa taille. (En théorie, nous pourrions faire comme d'autres entreprises en faisant le traitement sur un serveur, mais ce n'est pas ce que nous voulions. Et même si cela pouvait résoudre certains de nos problèmes, il conduirait à beaucoup d'autres défis spécifiques. Nous voulions aussi que nos utilisateurs puissent l'utiliser localement sans avoir recours à nos serveurs et à Internet). De plus, le modèle devait être raisonnablement rapide et aussi modeste en ce qui concerne la consommation de mémoire RAM / VRAM.
De plus, nous n'avions aucun ensemble de données que nous pouvions utiliser. Simo et Sierra ont utilisé un ensemble de données, où les images attendues ont toutes été dessinées en utilisant une largeur et une transparence de ligne constante, ce qui signifie que les résultats de l'entraînement possèdent aussi ces qualités. Nous voulions quelque chose qui ressemblait un peu plus à un dessin à main levée, en faisant varier les largeurs de ligne et des extrémités de lignes semi-transparentes. Ainsi, notre ensemble de données devait contenir ce genre d'images. Comme nous n'avons pas été au courant de tous les ensembles de données qui correspondent à nos exigences en matière de licence et du processus de collecte des données, nous avons demandé de l'aide à notre propre communauté. Vous pouvez lire ici le fil de discussions des artistes de Krita à ce sujet : https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401.
Le lien vers la totalité de notre ensemble de données se trouve ci-dessous dans la section « Ensemble de données ».
Architecture du modèle
Tous les calques principaux sont soit convolutionnels ou soit déconvolutionnels (À la fin du modèle). Après chaque calque (dé)convolutionnelle, à l'exception du dernier, il y a un calque d'activation « ReLu » et, après la dernière convolution, il y a un calque d'activation sigmoïde.
Paquets utilisés de Python : Pillow, Numpy, PyTorch et Openvino
Numpy est une bibliothèque standard pour toutes sortes de tableaux et d'opérations avancées de tableaux. Nous avons utilisé Pillow pour lire des images et les convertir en tableaux pour la bibliothèque « numpy » et vice versa. Pour l'entraînement, nous avons utilisé PyTorch, tandis que dans le module externe de Krita, nous avons utilisé Openvino pour l'inférence (Traitement grâce à l'accès au réseau).
Utilisation du processeur « NPU » pour l'inférence

Ce tableau montre le résultat de de l'outil « benchmark_app », fourni avec le paquet de Python « openvino » d'Intel. Il teste le modèle de manière isolée sur des données aléatoires. Comme vous pouvez le voir, le processeur NPU était plusieurs fois plus rapide que le processeur sur la même machine.
D'autre part, l'introduction d'un processeur « NPU » a rajouté un défi : les seuls modèles pouvant fonctionner sur ce processeur « NPU » sont des modèles statiques, ce qui signifie que la taille de l'entrée est connue au moment de l'enregistrement du modèle dans le fichier. Pour résoudre ce problème, le module externe découpe d'abord le canevas en très petites parties d'une taille spécifiée (Qui dépend du fichier de modèle), puis procède ensuite au traitement de tous ceux-ci et enfin rassemble tous les résultats ensemble. Pour éviter les artefacts sur les zones à côté des frontières, toutes des parties sont découpées avec un peu de marge et la marge est découpée plus tard.
Comment former votre propre modèle
Pour entraîner votre propre modèle, vous aurez besoin de compétences techniques, ainsi que des images (Entrée et sortie attendue) et d'un ordinateur puissant. Vous pourriez également avoir besoin de beaucoup d'espace sur votre disque dur, bien que vous puissiez simplement supprimer les anciens modèles inutiles si vous commencez à avoir des problèmes de manque d'espace.
Pilotes et préparation
Vous devrez installer Python3 et les paquets suivants : pillow, openvino, numpy, torch. Pour la quantification du modèle, vous aurez également besoin des paquets nncf et sklearn. Si j'ai manqué quelque chose, vous aurez un message d'erreur, alors installez simplement les paquets qui seront mentionnés en plus.
Si vous êtes sous Windows, vous avez probablement des pilotes dédiés aux processeurs « NPU » et « GPU ». Sous Linux, vous devrez peut-être installer des pilotes pour le processeur « NPU » avant de pouvoir l'utiliser : https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html .
De plus, si vous souhaitez utiliser un composant « iGPU » pour l'entraînement (Qui pourrait encore être beaucoup plus rapide que sur un processeur), vous aurez probablement besoin d'utiliser quelque chose comme « IPEX » permettant à PyTorch d'utiliser un périphérique « XPU », qui est juste votre composant « iGPU ». Il n'est pas testé ou recommandé puisque je n'ai personnellement pas été en mesure de l'utiliser parce que ma version de Python était supérieure à ce que l'instruction ne le prévoit. Mais, l'instruction est ici : https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu .
La vérification de l'état de santé de l'installation est la suivante :
python3 -c "import torch; import intel_extension_for_pytorch as ipex; print(f'Packages versions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Devices:'); print(f'Torch XPU device count: {torch.xpu.device_count()}'); [print(f'[Device {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
Il doit afficher plus de 0 périphérique ayant certaines propriétés de base.
Si vous parvenez à faire fonctionner le périphérique « XPU » sur votre ordinateur, vous aurez toujours besoin de modifier les scripts d'entraînement pour qu'ils puissent les utiliser : [https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html] (https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html) (Le plus probablement, vous devrez ajouter cette ligne :
import intel_extension_for_pytorch as ipex
au script tout en haut, juste en dessous de « import torch » et utilisez « xpu » comme nom de périphérique lorsque du lancement du script et cela devrait fonctionner. Mais comme je l'ai dit, les scripts n'ont pas été testé pour cela.
Ensemble de données
Vous aurez besoin de quelques photos pour pouvoir entraîner votre modèle. Les images doivent être par paires, chaque paire doit contenir un croquis (Entrée) et une image de dessin au trait (Sortie attendue). Plus l'ensemble de données est de qualité, meilleurs sont les résultats.
Avant l'entraînement, il est préférable d'augmenter les données : cela signifie que les images sont retournées, mises à l'échelle ou réduites et mises en miroir. Actuellement, le script d'augmentation de données effectue également une inversion en supposant que l'entraînement sur des images inversées apporterait les résultats plus rapidement (Étant donné que le noir signifie zéro, c'est à dire aucun signal. Et nous aimerions que ce soit l'arrière-plan, de sorte que les modèles apprennent les lignes, et non l'arrière-plan autour des lignes).
La façon d'utiliser le script d'augmentation de données est expliquée ci-dessous avec des instructions détaillées pour la partie concernant l'entraînement.
Voici l'ensemble de données que nous avons utilisé (Veuillez lire attentivement la licence si vous souhaitez l'utiliser) : https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
Choix du modèle et d'autres paramètres
Pour des résultats rapides, utilisez « tooSmallConv ». Si vous avez plus de temps et de ressources, « typicalDeep » pourrait être une meilleure idée. Si vous avez accès à un ordinateur avec un processeur graphique puissant, vous devriez essayer « original » ou « originalSmaller », qui représentent la description originale du modèle de l'article du Siggraph de Simo-Sierra 2016 et une version plus petite de celui-ci.
Utilisez le module « adadelta » comme optimiseur.
Vous pouvez utiliser « blackWhite » ou « mse » comme fonction de perte, « mse » est classique, mais « blackWhite » peut conduire à des résultats plus rapides car il réduit l'erreur relative sur les zones entièrement blanches ou entièrement noires (En fonction de l'image de sortie attendue).
Formation
Cloner le dépôt à https://invent.kde.org/tymond/fast-line-art (at 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.gitEnsuite, préparez le dossier :
- Créer un nouveau dossier pour l'entraînement.
- Dans le dossier, veuillez lancer :
python3 [dossier du dépôt]/spawnExperiment.py --path [chemin d'accès au nouveau dossier, relatif ou absolu] --note "[votre note personnelle sur l'expérience]"
Préparer les données :
- Si vous avez déjà un ensemble de données augmenté, veuillez l'insérer dans le dossier « data/training/ et data/verify/ », en gardant à l'esprit que les images appariées dans les sous-dossiers « ink/ » et « sketch/ » doivent avoir exactement les mêmes noms (Par exemple, si vous avez « sketch.png » et « ink.png » comme données, vous devez en mettre une dans le dossier « sketch/ » comme « picture.png » et une autre dans le dossier « ink/ » comme « picture.png » pour être appariée).
- Si vous n'avez pas d'ensemble augmenté et existant de données :
- Mettez toutes vos données brutes dans le dossier « data/raw/ », en gardant à l'esprit que les images appariées doivent avoir exactement les mêmes noms avec le préfixe ajouté soit « ink_ » soit « sketch_ » (Par exemple, si vous avez « picture\ _1.png » étant l'image du croquis et « picture\ _2.png » étant l'image de l'encrage, vous devez les nommer « sketch\ _picture.png » et « ink_picture.png » respectivement.)
- Lancez le script du préparateur de données :
python3 [dossier du dépôt]/dataPreparer.py-t taskfile.yml
Cela augmentera les données dans le répertoire « RAW » afin que l'entraînement soit plus réussi.
Modifiez le fichier « taskfile.yml » selon vos besoins. Les éléments les plus importants que vous souhaitez modifier sont :
- type de modèle\ - nom de code pour le type de modèle. Veuillez utiliser tinyTinier, tooSmallConv, typicalDeep ou tinyNarrowerShallow
- optimiseur - Type d'optimiseur. Veuillez utiliser « adadelta » ou « sgd »
- taux d'apprentissage- taux d'apprentissage pour sgd si en cours d'utilisation
- fonction de perte- nom de code pour la fonction de perte. Utilisez « mse » pour l'erreur quadratique moyenne (Mean Squared Error) ou « blackWhite » pour une fonction personnalisée de perte reposant sur « mse », mais un peu plus petite pour les pixels où la valeur de pixel de l'image cible est proche de 0,5.
Exécutez le code de d'entraînement :
python3 [dossier de dépôt]/train.py -t taskfile.yml -d "cpu"Sous Linux, si vous souhaitez qu'il s'exécute en arrière-plan, ajoutez le caractère « & » à la fin de la commande. S'il s'exécute en avant-plan, vous pouvez suspendre l'entraînement simplement en appuyant sur les touches « CTRL » + « C ». S'il s'exécute en arrière-plan, veuillez trouvez un identifiant de processus (En utilisant la commande « jobs -l » ou la commande « ps aux | grep train.py », le premier numéro qui devrait être l'identifiant de processus). Ensuite, tuez-le en utilisant la commande « kill [ID processus] ». Vos résultats seront toujours dans le dossier et vous pourrez reprendre l'entraînement à l'aide de la même commande.
Convertissez le modèle en un modèle openvino :
python3 [dossier du dépôt]/modelConverter.py-s [taille de l'entrée, 256 recommandé]\ -t [nom du modèle d'entrée, à partir de pytorch] -o [nom du modèle openvino qui doit se terminer par .xml]Placez les fichiers de modèle « .xml » et « .bin » dans votre dossier de ressources pour Krita (à l'intérieur du sous-dossier pykrita/fast_sketch_cleanup) aux côtés d'autres modèles pour les utiliser dans le module externe.