Digging into the Fast Sketch Cleanup Plugin for Krita
Fast Sketch Cleanup plugin
Introduction
We started this project with the intent of providing users a tool helpful in inking sketches. It is based on a research article by Simo & Sierra published in 2016, and it uses neural networks (now commonly called simply AI) to work. The tool has been developed in partnership with Intel and it’s still considered experimental, but you can already use it and see the results.
In the section below there are some real life examples of use cases and the results from the plugin. The results vary, but it can be used for extracting faint pencil sketches from photos, cleaning up lines, and comic book inking.
Regarding the model used in the tool, we trained it ourselves. All the data in the dataset is donated from people who sent their pictures to us themselves and agreed on this specific use case. We haven’t used any other data. Moreover, when you use the plugin, it processes locally on your machine, it doesn’t require any internet connection, doesn’t connect to any server, and no account is required either. Currently it works only on Windows and Linux, but we’ll work on making it available on MacOS as well.
Use cases
It averages the lines into one line and creates strong black lines, but the end result can be blurry or uneven. In many cases however it still works better than just using a Levels filter (for example in extracting the pencil sketch). it might be a good idea to use Levels filter after using the plugin to reduce the blurriness. Since the plugin works best with white canvas and grey-black lines, in case of photographed pencil sketches or very light sketch lines, it might be a good idea to use Levels also before using the plugin.
Extracting photographed pencil sketch
This is the result of the standard procedure of using Levels filter on a sketch to extract the lines (which results in a part of the image getting the shadow):

sketch_girl_original_procedure_comparison_small1843×1209 165 KB
The sketch was drawn by Tiar (link to KA profile)
This is the procedure using the plugin with SketchyModel (Levels → plugin → Levels):

sketch_girl_new_procedure_comparison_small1843×2419 267 KB
Comparison (for black lines):

sketch_girl_procedures_comparison_small1920×1260 215 KB
Another possible result is to just stop at the plugin without forcing black lines using Levels, which results in a nicer, more pencil-y look while keeping the lower part of the page still blank:

sketch_girl_after_plugin_small1536×2016 161 KB
Comic book-like inking
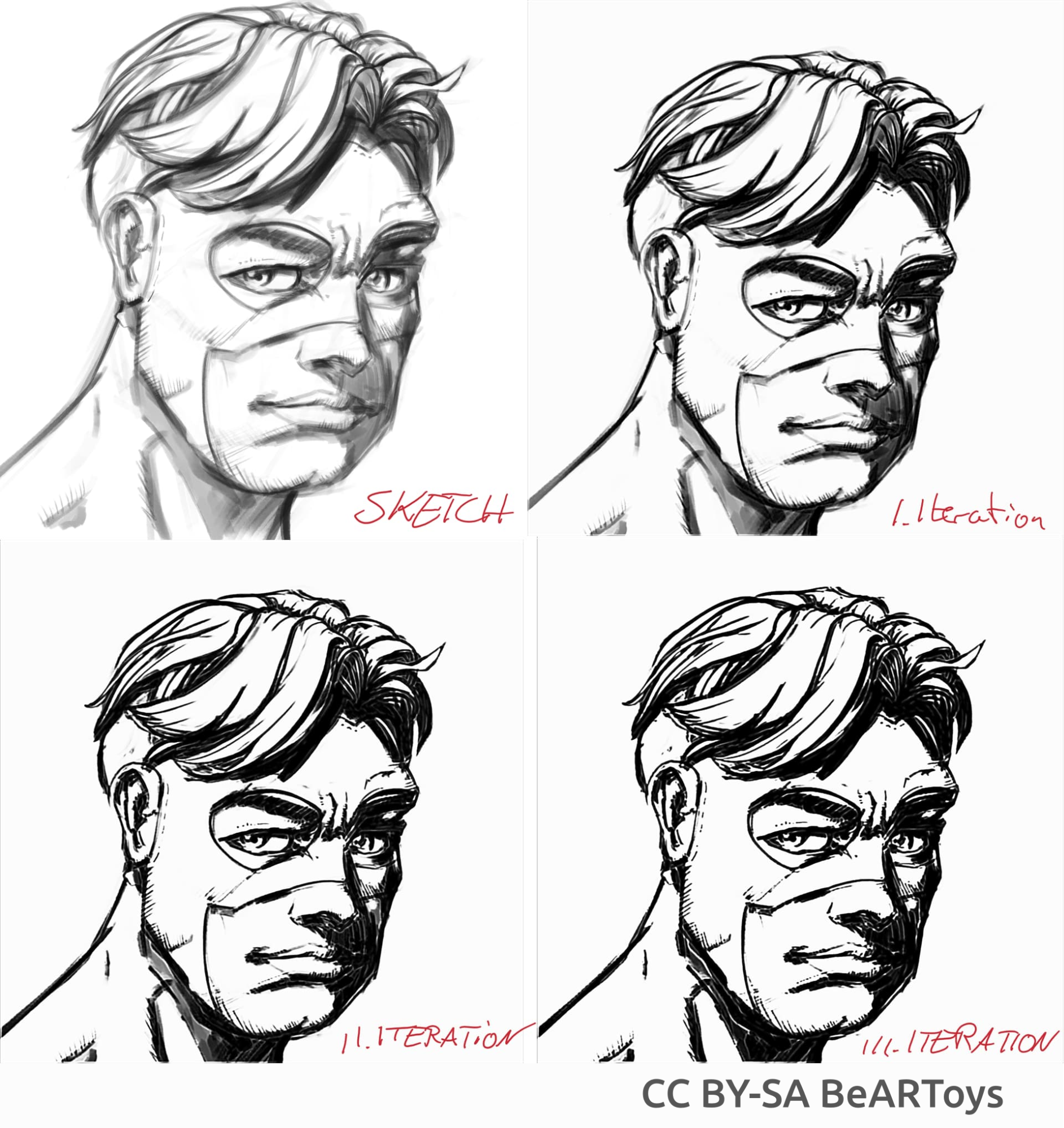
Picture of a man made by BeARToys

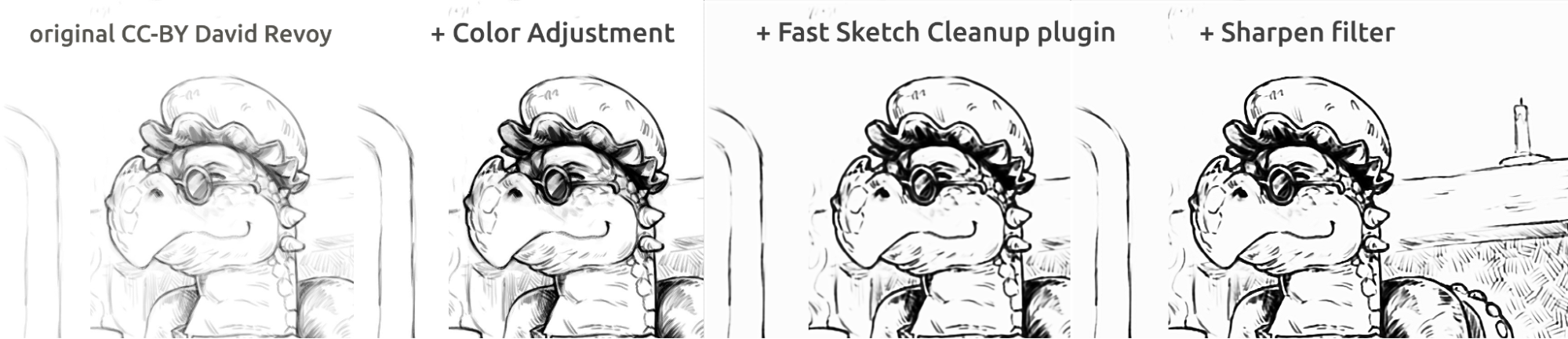
Here in the pictures above you can see the comic book style inking. The result, which is a bit blurry compared to the original, can be further enhanced by using a Sharpen filter. The dragon was sketched by David Revoy (CC-BY 4.0).
Cleaning up lines
Examples of sketches I made and the result of the plugin, showing the strong and weak points of the plugin. All of the pictures below were made using the SketchyModel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

flower_001_detail681×456 22.1 KB
{kind=link}

portrait_man_portrait_2_comparison_2_small1305×505 139 KB
{kind=link}

portrait_man_portrait_2_detail646×1023 26.6 KB
{kind=link}
All of the pictures above painted by Tiar (link to KA profile)
On the pictures below, on the scales of the fish, you can see how the model discriminates lighter lines and enhances the stronger lines, making the scales more pronounced. In theory you could do that using the Levels filter, but in practice the results would be worse, because the model takes into account local strength of the line.
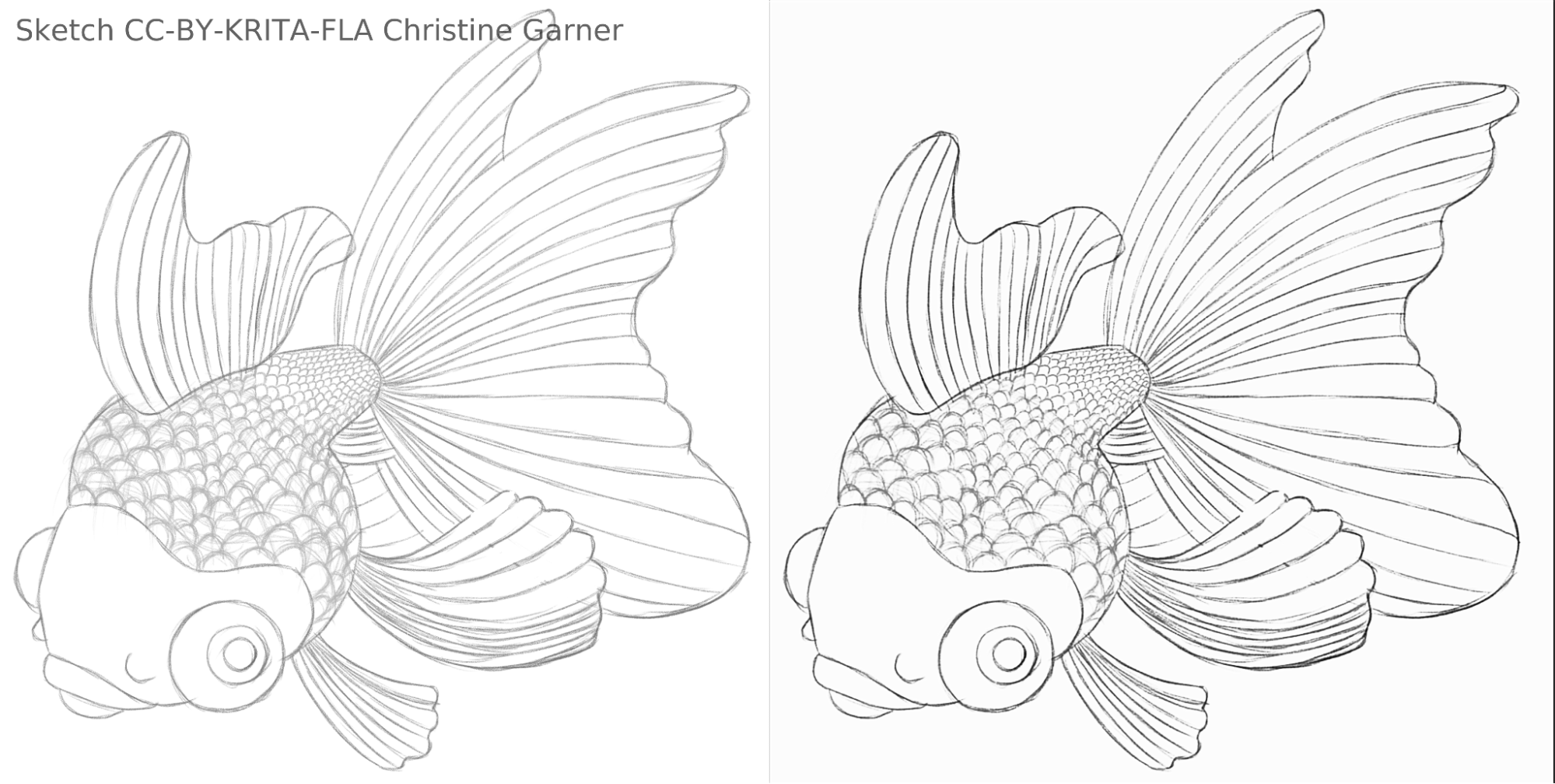
fish_square_sketchy_comparison_small1920×968 156 KB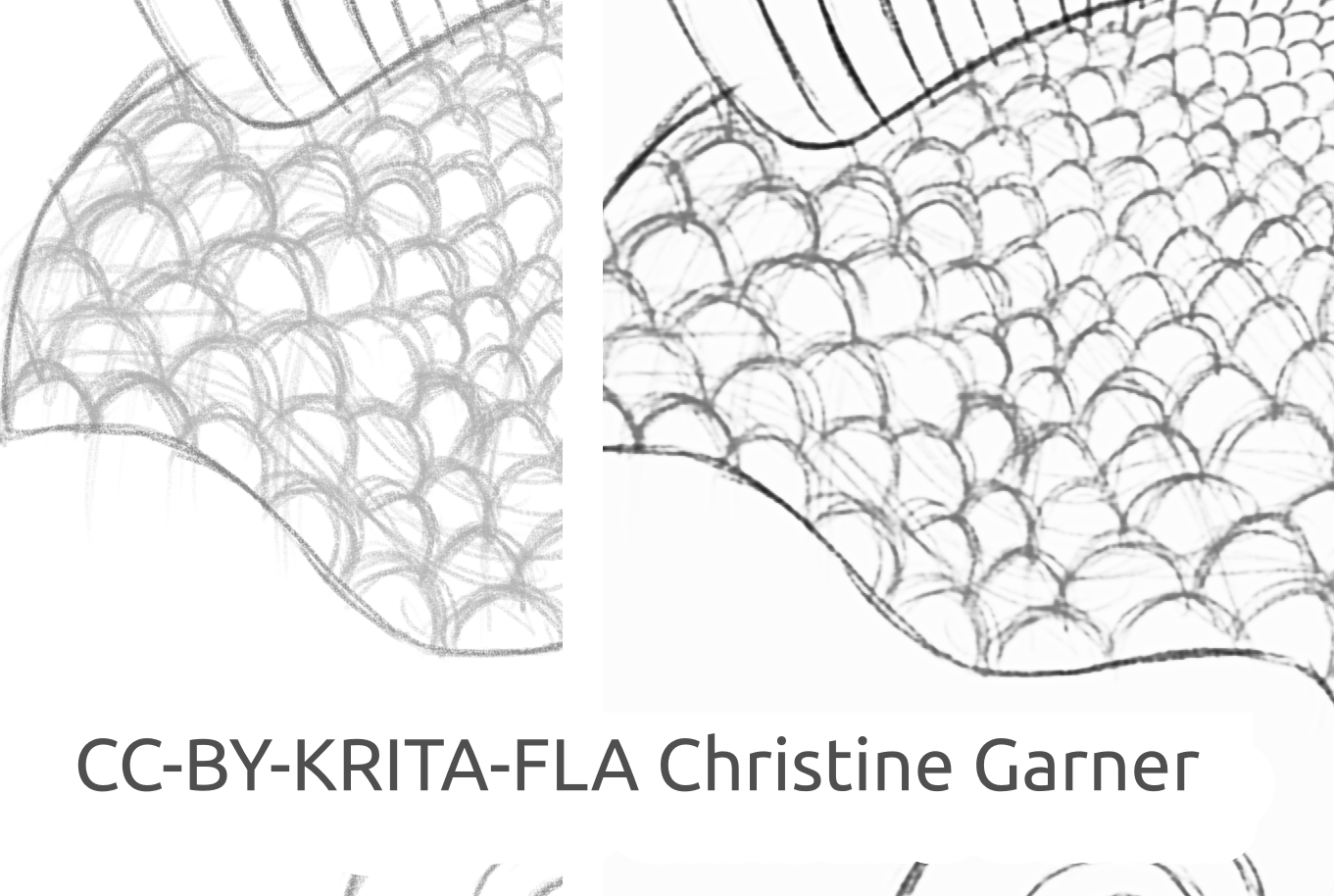
{kind=link}
Picture of the fish made by Christine Garner (link to portfolio)
How to use it in Krita
To use the Fast Sketch Cleanup plugin in Krita, do the following:
Prepare Krita:
On Windows:
Either in one package: download Krita 5.3.0-prealpha with Fast Sketch Cleanup plugin already included: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-x64-5.3.0-prealpha-cdac9c31.zip
Or separately:
- Download portable version of Krita 5.2.6 (or similar version - should still work)
- Download separately the Fast Sketch Cleanup plugin here: https://download.kde.org/stable/krita/FastSketchPlugin-1.0.2/FastSketchPlugin1.0.2.zip
- Unzip the file into krita-5.2.6/ folder (keeping the folder structure).
- Then go to Settings → Configure Krita → Python Plugin Manager, enable Fast Sketch Cleanup plugin, and restart Krita.
On Linux:
- Download the appimage: https://download.kde.org/unstable/krita/5.3.0-prealpha-fast-sketch/krita-5.3.0-prealpha-cdac9c31c9-x86_64.AppImage
(Optional) Install NPU drivers if you have NPU on your device (practically only necessary on Linux, if you have a very new Intel CPU): Configurations for Intel® NPU with OpenVINO™ — OpenVINO™ documentation (note: you can still run the plugin on CPU or GPU, it doesn’t require NPU)
Run the plugin:
- Open or create a white canvas with grey-white strokes (note that the plugin will take the current projection of the canvas, not the current layer).
- Go to Tools → Fast Sketch Cleanup
- Select the model. Advanced Options will be automatically selected for you.
- Wait until it finishes processing (the dialog will close automatically then).
- See that it created a new layer with the result.
Advice for processing
Currently it’s better to just use the SketchyModel.xml, in most cases it works significantly better than the SmoothModel.xml.
You need to make sure the background is pretty bright, and the lines you want to keep in the result are relatively dark (either somewhat dark grey or black; light grey might result in many missed lines). It might be a good idea to use a filter like Levels beforehand.
After processing, you might want to enhance the results with either Levels filter or Sharpen filter, depending on your results.
Technology & Science behind it
Unique requirements
First unique requirement was that it had to work on canvases of all sizes. That meant that the network couldn’t have any dense/fully or densely connected linear layers that are very common in most of the image processing neural networks (which require input of a specific size and will produce different results for the same pixel depending on its location), only convolutions or pooling or similar layers that were producing the same results for every pixel of the canvas, no matter the location. Fortunately, the Simo & Sierra paper published in 2016 described a network just like that.
Another challenge was that we couldn’t really use the model they created, since it wasn’t compatible with Krita’s license, and we couldn’t even really use the exact model type they described, because one of those model files would be nearly as big as Krita, and the training would take a really long time. We needed something that would work just as well if not better, but small enough that it can be added to Krita without making it twice as big. (In theory, we could do like some other companies and make the processing happen on some kind of a server, but that wasn’t what we wanted. And even if it resolved some of our issues, it would provide plenty of its own major challenges. Also, we wanted for our users to be able to use it locally without a reliance on our servers and the internet). Moreover, the model had to be reasonably fast and also modest in regards to RAM/VRAM consumption.
Moreover, we didn’t have any dataset we could use. Simo & Sierra used a dataset, where the expected images were all drawn using a constant line width and transparency, which meant that the results of the training had those qualities too. We wanted something that looked a bit more hand-drawn, with varying line-width or semi-transparent ends of the lines, so our dataset had to contain those kinds of images. Since we haven’t been aware of any datasets that would match our requirements regarding the license and the data gathering process, we asked our own community for help, here you can read the Krita Artists thread about it: https://krita-artists.org/t/call-for-donation-of-artworks-for-the-fast-line-art-project/96401 .
The link to our full dataset can be found below in the Dataset section.
Model architecture
All main layers are either convolutional or deconvolutional (at the end of the model). After every (de)convolutional layer except for the last one there is a ReLu activation layer, and after the last convolution there is a sigmoid activation layer.
Python packages used: Pillow, Numpy, PyTorch and Openvino
Numpy is a standard library for all kinds of arrays and advanced array operations and we used Pillow for reading images and converting them into numpy arrays and back. For training, we used PyTorch, while in the Krita plugin we used Openvino for inference (processing through the network).
Using NPU for inference

This table shows the result of benchmark_app, which is a tool that’s provided with Intel’s python package openvino. It tests the model in isolation on random data. As you can see, the NPU was several times faster than the CPU on the same machine.
On the other hand, introducing NPU added a challenge: the only models that can run on NPU are static models, meaning the input size is known at the time of saving the model to file. To solve this, the plugin first cuts the canvas into smaller parts of a specified size (which depends on the model file), and then proceeds to process all of them and finally stitch the results together. To avoid artifacts on the areas next to the stitching, all of the parts are cut with a little bit of a margin and the margin is later cut off.
How to train your own model
To train your own model, you’ll need some technical skills, pairs of pictures (input and the expected output) and a powerful computer. You might also need quite a lot of space on your hard drive, though you can just remove unnecessary older models if you start having issues with lack of space.
Drivers & preparation
You’ll need to install Python3 and the following packages: Pillow, openvino, numpy, torch. For quantization of the model you will also need nncf and sklearn. If I missed anything, it will complain, so just install those packages it mentions too.
If you’re on Windows, you probably have drivers for NPU and dedicated GPU. On Linux, you might need to install NPU drivers before you’ll be able to use it: https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html .
Moreover if you want to use iGPU for training (which might still be significantly faster than on CPU), you’ll probably need to use something like IPEX which allows PyTorch to use an “XPU” device, which is just your iGPU. It’s not tested or recommended since I personally haven’t been able to use it because my Python version was higher than the instruction expects, but the instruction is here: https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10%2Bxpu .
The sanity check for the installation is as follows:
python3 -c "import torch; import intel_extension_for_pytorch as ipex; print(f'Packages versions:'); print(f'Torch version: {torch.__version__}'); print(f'IPEX version: {ipex.__version__}'); print(f'Devices:'); print(f'Torch XPU device count: {torch.xpu.device_count()}'); [print(f'[Device {i}]: {torch.xpu.get_device_properties(i)}') for i in range(torch.xpu.device_count())];"
It should show more than 0 devices with some basic properties.
If you manage to get XPU device working on your machine, you’ll still need to edit the training scripts so they’ll able to use it: https://intel.github.io/intel-extension-for-pytorch/xpu/latest/tutorials/getting_started.html (most probably you’ll just need to add this line:
import intel_extension_for_pytorch as ipex
to the script on the very top, just underneath “import torch”, and use “xpu” as the device name when invoking the script, and it should work. But as I said, the scripts hasn’t been tested for that.
Dataset
You’ll need some pictures to be able to train your model. The pictures must be in pairs, every pair must contain a sketch (input) and a lineart picture (expected output). The better quality of the dataset, the better the results.
Before training, it’s best if you augment the data: that means the pictures are rotated, scaled up or down, and mirrored. Currently the data augmentation script also performs an inversion with the assumption that training on inverted pictures would bring the results faster (considering that black means zero means no signal, and we’d like that to be the background, so the models learn the lines, not the background around lines).
How to use the data augmentation script is explained below in the detailed instruction for the training part.
Here’s the dataset that we used (please read the license carefully if you want to use it): https://files.kde.org/krita/extras/FastSketchCleanupPluginKritaDataset.zip
Choice of model and other parameters
For quick results, use tooSmallConv; if you have more time and resources, typicalDeep might be a better idea. If you have access to a powerful GPU machine, you might try original or originalSmaller, which represent the original description of the model from the SIGGRAPH article by Simo-Sierra 2016, and a smaller version of it.
Use adadelta as the optimizer.
You can use either blackWhite or mse as the loss function; mse is classic, but blackWhite might lead to faster results since it lowers the relative error on the fully white or fully black areas (based on the expected output picture).
Training
Clone the repository at https://invent.kde.org/tymond/fast-line-art (at 33869b6)
git clone https://invent.kde.org/tymond/fast-line-art.gitThen, prepare the folder:
- Create a new folder for the training.
- In the folder, run:
python3 [repository folder]/spawnExperiment.py --path [path to new folder, either relative or absolute] --note "[your personal note about the experiment]"
Prepare data:
- If you have existing augmented dataset, put it all in data/training/ and data/verify/, keeping in mind that paired pictures in ink/ and sketch/ subfolders must have the exact same names (for example if you have sketch.png and ink.png as data, you need to put one in sketch/ as picture.png and another in ink/ as picture.png to be paired).
- If you don't have existing augmented dataset:
- Put all your raw data in data/raw/, keeping in mind that paired pictures should have the exact same names with added prefix either ink_ or sketch_ (for example if you have picture_1.png being the sketch picture and picture_2.png being the ink picture, you need to name them sketch_picture.png and ink_picture.png respectively.)
- Run the data preparer script:
python3 [repository folder]/dataPreparer.py -t taskfile.yml
That will augment the data in the raw directory in order for the training to be more successful.
Edit the taskfile.yml file to your liking. The most important parts you want to change are:
- model type - code name for the model type, use tinyTinier, tooSmallConv, typicalDeep or tinyNarrowerShallow
- optimizer - type of optimizer, use adadelta or sgd
- learning rate - learning rate for sgd if in use
- loss function - code name for loss function, use mse for mean squared error or blackWhite for a custom loss function based on mse, but a bit smaller for pixels where the target image pixel value is close to 0.5
Run the training code:
python3 [repository folder]/train.py -t taskfile.yml -d "cpu"On Linux, if you want it to run in a background, add “&” at the end. If it runs in a foreground, you can pause the training just by pressing ctrl+C, and if it runs in a background, find a process id (using either “jobs -l” command or “ps aux | grep train.py” command, the first number would be the process id) and kill it using “kill [process id]” command. Your results will still be in the folder, and you’ll be able to resume the training using the same command.
Convert the model to an openvino model:
python3 [repository folder]/modelConverter.py -s [size of the input, recommended 256] -t [input model name, from pytorch] -o [openvino model name, must end with .xml]Place both the .xml and .bin model files in your Krita resource folder (inside pykrita/fast_sketch_cleanup subfolder) alongside other models to use them in the plugin.